Objections to Frequentism
8/14/18
(Updated 7/23/22)
Hello. I'm a use whatever works type of mathematical statistician: frequentism, nonparametric, machine learning, Bayesian, operations research, SAS, Python, Excel, whatever. However, after reading, hearing, and collecting many arguments against frequentism, some of them contradicting, and most of them containing fallacies rehashed year after year, I decided to write this article in response.
"Frequentism" is roughly defined as:
- frequentist definition of probability
- Implicit in Aristotle, but see
- System of Logic, by John Stuart Mill
- The Theory of Probability and The Concept of Probability in the Mathematical Representation of Reality, by Reichenbach
- The Logic of Chance, by Venn
- Probability, Statistics, and Truth and Mathematical Theory of Probability and Statistics, by von Mises
- Two main types, hypothetical (includes infinite), and finite
- Implicit in Aristotle, but see
- frequentist concept/practice of statistics
- sampling, sample space/distribution
- fixed/constant parameters
- hypothesis testing, commonly called "null hypothesis significance testing" or "NHST"
- Joint Statistical Papers, by Neyman and Pearson
- p-values, confidence intervals, fiducial probability/confidence distribution
- severity/severe testing, equivalence testing
- simulation, Monte Carlo, jackknife, bootstrap (see An Introduction to the Bootstrap , by Efron and Tibshirani), permutations
- And Statistical Methods for Research Workers, The Design of Experiments, and Statistical Methods and Scientific Inference, by Fisher fits in somewhere
Criticisms of Frequentism:
- 15 Arguments Against finite Frequentism and 15 Arguments Against Hypothetical Frequentism by Hajek
- The fallacy of the null-hypothesis significance test Rozeboom
- The Cult of Statistical Significance: How the Standard Error Costs Us Jobs, Justice, and Lives by Ziliak and McCloskey
- A Litany of Problems With p-values, My Journey From Frequentist to Bayesian Statistics, Null Hypothesis Significance Testing Never Worked, Bayesian vs. Frequentist Statements About Treatment Efficacy, and Language for communicating frequentist results about treatment effects by Harrell
- A Dirty Dozen: Twelve P-Value Misconceptions by Goodman
- Bernoulli's Fallacy: Statistical Illogic and the Crisis of Modern Science, by Clayton. See my review Clayton's Fallacy
- Significance tests as sorcery: Science is empirical- significance tests are not by Lambdin
- Uncertainty: The Soul of Modeling, Probability & Statistics, Everything Wrong With P-Values Under One Roof, Is Presuming Innocence A Bayesian Prior?, How Predictive Statistics Can Help Alleviate, But Not Eliminate, The Reproducibility Crisis, The Replacement for Hypothesis Testing, and More Proof Hypothesis Testing Is Wrong & Why The Predictive Method Is The Only Sane Way To Do Statistics by Briggs
- The earth is flat (p > 0.05): significance thresholds and the crisis of unreplicable research, Scientists rise up against statistical significance, and Inferential Statistics as Descriptive Statistics: There Is No Replication Crisis if We Don't Expect Replication by Amrhein et al
- An Applied Statistician's Creed by Nester
- Damaging Real Lives Through Obstinacy: Re-Emphasising Why Significance Testing is Wrong and What to do instead of significance testing? Calculating the 'number of counterfactual cases needed to disturb a finding' by Gorard
- Cumming's Dance of P-Values, and a similar dance by Dragicevic
- Probability Theory: The Logic of Science, by Jaynes
Responses to Criticisms of Frequentism:
Frequency definition of probability
- Frequentism does not take all types of uncertainty into account, so it cannot hold as a
concept of probability Frequentism is the definition or gold standard of probability. Much like a specific science limits their field of study to be well-defined, frequentism purposefully limits probability to be long-term relative frequency instead of admitting any type of general uncertainty to be the same status as probability. A frequentist certainly could model some of these types of uncertainty, but understands it becomes an exercise of modelling using strong assumptions, not studying probability per se. This is not to say that studying non-relative frequency interpretations is unimportant, or that you shouldn't learn about it or do it, however.
I like to explain the difference in uncertainty/chance/belief and probability by comparing paleontologists and geologists. A paleontologist is an expert in fossils (not rocks) and a geologist is an expert in rocks (not fossils). While digging, a paleontologist might find rocks and a geologist might find fossils. It would be a mistake for either to think fossils are rocks and have expertise with it just because they are both hard, look similar, and found in the ground.
Additionally, despite popular belief, frequentism is not confined to only a frequency definition of probability. There are frequentists that have no problem distinguishing and switching between aleatory (seen in nature or society) and epistemic (our confidence or knowledge) probabilities, and moreover this can be done without needing Bayesian priors. Schweder and Hjort in Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions note that "The Bayesian, on the other hand, only has one form of probability, and has no choice but to regard parameters as stochastic variables".
Some critics of frequentism remind me of critics of the distant past of limits from calculus, who referred to "ghosts of departed quantities". Limits, asymptotics, frequentism, simply work.
- Frequentism cannot handle n = 1 or one-time events. No approaches of probability or statistics have very satisfactory answers for n = 1 or small sample or one-time events. For n = 1 you can only have 0% or 100% if using relative frequency to define probability. In some cases we can assign probability to single events using a prediction rule. For example, P(An+1) = xbarn, where it is just a matter of choosing an appropriate statistical model, as Spanos notes, and making your assumptions known. There is also a "many worlds" interpretation of frequentism, and that refers to the "sci-fi" idea that say for a one-time event with probability p = X/N, the event occurred in X worlds out of the N worlds, and this one-time event just happened to occur in our world. To some (but not to me) this "answers" the paradox of trying to supply a probability for one-time events using frequentism. The frequentist could also simply use Bayes rule, which is fully in the frequentist domain when it involves general events and not probability distributions on parameters. Moreover, if there is, say, an expensive event which cannot be replicated, then (I think obviously?) it would be broken down to smaller parts that can each be replicated physically or simulated.
- Strong Law of Large Numbers (SLLN) says that it is almost certain that between the mth and nth observations in a group of length n, the relative frequency of Heads will remain near the fixed value p, whatever p may be (ie. doesn't have to be 1/2), and be within the interval [p-ε, p+ε], for any small ε > 0, provided that m and n are sufficiently large numbers. That is, P(Heads) in [p-ε, p+ε] > 1 - 1/(m*ε2). von Mises talked about such sequences, Wald proved their existence, and Kolmogorov even rested his axiomatic probability on it.
- Kolmogorov axioms have too much frequentist baggage On the contrary, when going from the mathematical to the real world, Kolmogorov himself noted in his On Tables of Random Numbers the contribution of von Mises
"...the basis for the applicability of the results of the mathematical theory of probability to real 'random phenomena' must depend on some form of the frequency concept of probability, the unavoidable nature of which has been established by von Mises in a spirited manner."
As well as in his Foundations of the Theory of Probability
"In establishing the premises necessary for the applicability of the theory of probability to the world of actual events, the author has used, in large measure, the work of R. v. Mises"
Other critics have mentioned that that nowhere in Kolmogorov's mathematical axioms is a frequency interpretation mentioned. Of course, this is in contradiction to the other critics that have mentioned his theorems have too much frequentist baggage.
In Probability Theory: The Logic of Science, by Jaynes, he writes
"KSP [Kolmogorov axioms -Justin] has been criticized as lacking connection to the real world; it has seemed to some that its axioms are deficient because they contain no statement to the effect that the measure P is to be interpreted as a frequency in a random experiment.1 But, from our viewpoint, this appears as a merit rather than a defect; to require that we invoke some random experiment before using probability theory would have imposed an intolerable and arbitrary restriction on the scope of the theory, making it inapplicable to most of the problems that we propose to solve by extended logic.
1 Indeed, de Finetti (1972, p. 89) argues that Kolmogorov's system cannot be interpreted in terms of limits of frequencies."
Apparently de Finetti and Jaynes were unaware of Kolmogorov recognizing the fundamental connection frequencies have to the real world.
- Cox theorem = Bayes and probability as logic approach Unfortunately, Cox's development, which was mainly copied by Jaynes in his Probability Theory: The Logic of Science, was not rigorous. See A Counterexample to Theorems of Cox and Fine by Halpern and Cox's Theorem Revisited by Halpern. In The Philosophical Significance of Cox’s Theorem by Colyvan, he questions fundamental assumptions in Cox's theorem. In Cox's Theorem and the Jaynesian Interpretation of Probability by Terenin and Draper, they say "Unfortunately, most existing correct proofs of Cox's Theorem require restrictive assumptions: for instance, many do not apply even to the simple example of rolling a pair of fair dice". Currently Cox's theorem is trying to be patched up. Although, it clearly lost its luster and intuition from when it was first introduced (which may partially explain why the frequency interpretation of probability and statistics is most popular). See Bridging the intuition gap in Cox's theorem by Clayton and Waddington.
- Referring to coin flip experiments is too simplistic to be useful for real life On the contrary, these are the simplest experiments to discuss probability and statistics so we don't get bogged down in details/weeds and get off course. Note that in a coin flip experiment (I'm not talking about statistics or mathematics here, but just the experiment) one does not need to refer to any likelihood or prior.
- How do you know frequencies are stable/converging? The Strong Law of Large Numbers (SLLN) provides the mathematical theory, but one can simply observe, in coin flip experiments for example, the relative frequency of heads settling down to a horizontal line, and it gets closer as the number of flips increase. What is this limiting behavior if not "probability"? It certainly isn't a subjective belief.
- There are repetitive events that have probabilities that don't converge, and this refutes the frequentist notion of probability. Actually, this refutes that these specific sequences have anything to do with probability, which was never claimed in the first place by frequentists. As von Mises and Wald detail, the properties of the sequences are very specific, for example convergence and the irrelevance of place selection (randomness).
- You can never observe an infinite amount of trials Well one can never actually observe an infinite amount of infinitely skinnier rectangles under a curve, but we are confident integration (area under a curve) works. The long-term relative frequency "settles down" in [p-ε, p+ε] by the Strong Law of Large Numbers (SLLN) for any small ε>0. We can get closer and closer to p, whatever p is. In our finite world, we can say that for any very small d>0, if, at the end of n trials, |fn-p| < d, then we are justified in saying fn~p (read "fn is approximately p") for all intents and purposes. If the "true" p is .5, for example, do you worry if the observed relative frequency is .4999999999 or .500000001? Engineers don't need to take all digits of π (= 3.14159...) into account to do engineering. There are, however, also finite versions of the laws of large numbers. I'd say if infinity is too large, how about we agree on 1,000,000,000 (much less than infinity)? Why, if we already have at least 1 trial, and we actively plan for replication in science, is the notion of repeating trials, even hypothetically, unbelievable?
- The "relies on infinite number of trials" and "bad for one-time events" charges both ignore the middle-ground of finite frequentism. Also, Frequentist Inference without Repeated Sampling by Vos and Holbert, looks at an interpretation of frequentist inference that uses a single random sample instead of hypothetical repeated sampling.
- Bayesian updates probability, frequentism doesn't The Bayesian saying is "today's posterior is tomorrow's prior", even if that is rarely actually done in practice. However, a cumulative relative frequency "updates" itself over trials, and not using any beliefs. See Streaming mean and standard deviation, which discusses
relfreq(Heads)t+1 = ((t-1)*relfreq(Heads)t + It)/t, where
It = 1 if Heads is observed on the tth trial, 0 otherwiseOf course, the lessons learned and results from experiments are used to inform future experiments and projects. Are there examples of Bayesian updating (posteriort used as priort+1) being done long-term? I'd only rely on the results if they had good long-term frequentist properties. Updating will be bad if GI (from GIGO). Do Bayesians guarantee that at any time t along the way there will not be GI? See Compounding Errors showing the general idea of how small errors now can create big errors later on in a process. Owhadi wrote
How do you make sure that your predictions are robust, not only with respect to the choice of prior but also with respect to numerical instabilities arising in the iterative application of the Bayes rule?
Moreover, Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort, notes that instead of updating the prior/posterior distribution, updating can be done on the likelihood.
- The probability, as frequentists define it, can only be in the form a/b, where a and b are natural numbers An example of a problem for frequentism, a critic might say, is P(A and B) = P(A)*P(B) = 1/2, and P(A)=P(B). Therefore, P(A) = sqrt(2)/2. This is actually not an issue, as probability is in the limit or simply approximated. We could also argue no one would ever actually observe a probability of sqrt(2)/2, for example, but only the digits of what their measuring device is showing them with respect to sqrt(2). Additionally, I'd also rather be confined to ratios of natural numbers from experiments, and their limits, than allowing probability based on subjective beliefs.
- There is Bayesian uncertainty, propensity, and other definitions of probability or approaches Yes, and these are all inferior definitions or approaches (in my opinion). I address Bayesian primarily on this webpage. For the propensity approach, it relies on frequentism so it is redundant. For likelihood, see Why I am Not a Likelihoodist by Gandenberger. My summary is that it says that likelihoodism gives no good guidance for belief or action.
- Clearly parameters are random variables (Bayesian) and not fixed constants (frequentism) I'd say we are, of course, intuitively "uncertain" about the values of most parameters, but also that they are fixed constants, at least at a given time t. For example, what is the total weight for everyone in the United States right now (time = 1)? It is W1. Rather, I should say it was W1, but right now (time = 2) it is W2. The W1 and W2 were (and still are) certainly unknown constants. Is c, the speed of light, really a constant forever, or does it change over time, and we are just witnessing ct for the time period we are in? This is related to the poor "wear and tear" argument.
Frequentist concepts like hypothesis testing and p-values are too difficult to teach.
- My students or colleagues or clients get confused with the definition of p-values,
hypothesis testing, etc Students getting confused, or being an ineffective teacher, is not
any justification for concluding frequentism is flawed. I've personally advised a variety of people, groups, students, professionals, and have never had much problem communicating these concepts. With Bayesian credible intervals you are not really saying P(μ in interval) = .80, in my opinion, but are instead saying something like P(μ in interval | my personal beliefs/strong assumptions) = .80, or equivalently Belief(μ in interval) = .80, or Chance(μ in interval) = .80, or Uncertainty(μ in interval) = .80. Frequentism can also be easy to understand. Relative frequencies converge to probability, and we
can do experiments to show this. We can make errors when reasoning from data. P-values are
just test statistics expressed on another scale. P-values and confidence intervals over time make for good
science. Note that this contradicts the "frequentists don't want to deal with hard math" charge. Here are some graphs that can be used for teaching these concepts:
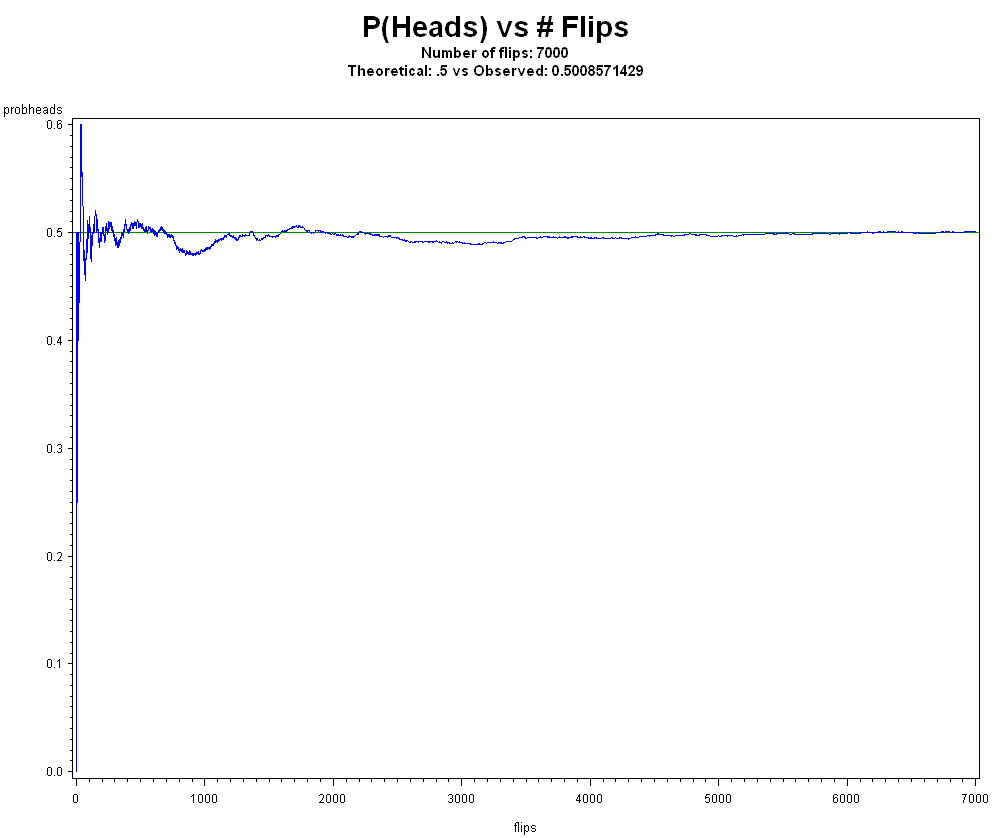
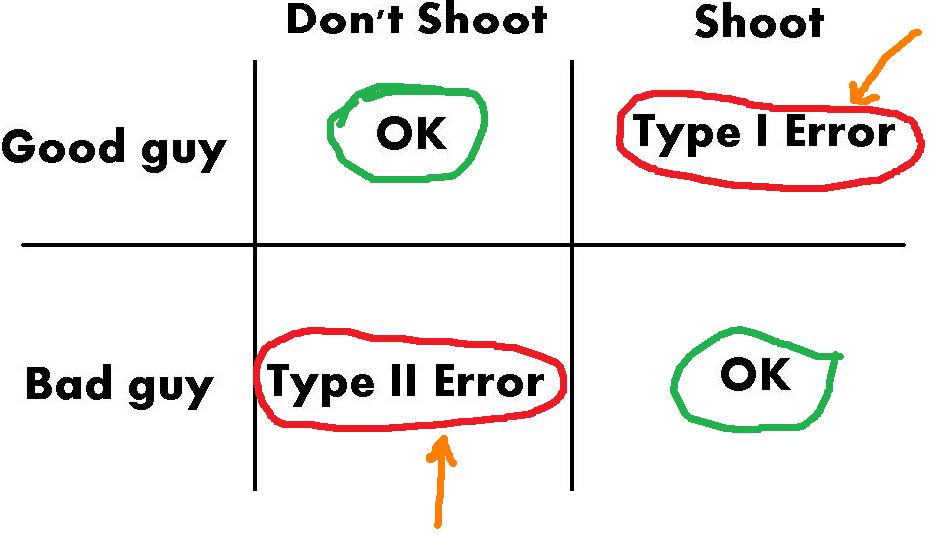

- Bayesian is "natural", we have "Bayesian brains" Is it natural to be forced to use Markov Chain Monte Carlo (MCMC) to solve problems? Is it natural to think of improper priors? Natural may simply not be a well-defined concept, but more like a preference. Keeping track of the number of times an event A occurs in N trials as N increases is more natural, in my opinion. Counts and histograms are examples of frequencies that are totally natural in probability and statistics.
- You can sometimes take a frequentist confidence interval and from it calculate implied Bayesian priors that are nonsensical, and therefore frequentist CIs are flawed One can also take a Bayesian posterior generating process and find that it has poor frequentist properties. The frequentist confidence interval, for larger and larger n, can make inferences that become independent of any prior. Also, there is no guarantee that your prior will match the prior of another, or not be brittle and subjective, so appealing to priors as the gold standard is not a great argument.
Also, please note that the Bernstein-von Mises theorem asserts that under some conditions, in the large sample limit the distribution of the frequentist maximum likelihood estimate is about the same as the Bayesian posterior distribution, so one can take Bayesian credible intervals as approximate frequentist confidence intervals and vice a versa. Of course, these conditions sometimes are not met in practice.
- Bayesian mathematics is harder and frequentists just don't want to put in the effort Many frequentists have put in the effort and found that Bayesian was over-promising and therefore they weren't "getting the bang for the buck", especially if for a lot of cases the two approaches give similar answers. Note this contradicts the "nuisance parameters are harder to deal with in frequentism" charge
- It is too easy to get a small p-value. This contradicts the "difficult to replicate small p-values" charge.
- It is too difficult to replicate small p-values that others found. This contradicts the "too easy to get a small p-value" charge.
- The concept of hypothesis testing is so odd. Why would anyone want to do hypothesis testing anyway? The idea of wanting to make statements about a population (ie. make an inference) from a sample is quite natural. There are, quite literally, many thousands of examples of hypothesis testing in scientific, and other, papers.
- Even scientists get confused with p-values! This may be true in some cases, although I doubt the same people getting confused with p-values and related logic will then somehow understand the intracacies of Bayesian priors and MCMC settings. However, consider Use of significance test logic by scientists in a novel reasoning task, by Morey and Hoekstra (and find their experiment and interactive app of results here and here). In the article abstract (bolding mine), they say
"Although statistical significance testing is one of the most widely-used techniques across science, previous research has suggested that scientists have a poor understanding of how it works. If scientists misunderstand one of their primary inferential tools the implications are dramatic: potentially unchecked, unjustified conclusions and wasted resources. Scientists' apparent difficulties with significance testing have led to calls for its abandonment or increased reliance on alternative tools, which would represent a substantial, untested, shift in scientific practice. However, if scientists' understanding of significance testing is truly as poor as thought, one could argue such drastic action is required. We show using a novel experimental method that scientists do, in fact, understand the logic of significance testing and can use it effectively. This suggests that scientists may not be as statistically-challenged as often believed, and that reforms should take this into account."
- Frequentist terms are too confusing. We should switch to using terms that align with Bayesian ideals. Some Bayesians, such as McElreath in his Bayesian Statistics without Frequentist Language talk, would like to make the following changes in our statistical vocabulary
ConventionProposalDataObserved variableParameterUnobserved variableLikelihoodDistributionPriorDistributionPosteriorConditional distributionEstimatebanishedRandombanished
This would be a mistake because data and parameters differ in more aspects than just observed and unobserved, likelihoods and priors are very different and have different uses even if both are "just distributions", and wanting to banish use of the terms "estimate" and "random" is just silly. One could probably argue that Bayesians may want to blur the differences between likelihoods and priors, and banish the words estimate and random, to blunt the criticism against problematic but fundamental Bayesian concepts and simultaneously diminish frequentist contributions. McElreath adds, however, that at times he uses these terms, that sometimes their use is OK, so determining exactly what he is proposing is rather confusing.
- Frequentists are cheating by making the definition of p-value be "observations as or more extreme", when it should just be equal to. Actually, everyone knows the probability of observing about any specific single continuous observation is small, so hence the "as or more extreme" in the definition. In other words, the definition makes it more difficult to reject a null hypothesis.
- It is silly to label a p-value as significant, suggestive, an indication, almost significant, nearly significant, trending, etc. That may be true. Consider these examples floating around (most of which I've never actually read or heard in real life):
(barely) not statistically significant (p=0.052), a barely detectable statistically significant difference (p=0.073), a borderline significant trend (p=0.09), a certain trend toward significance (p=0.08), a clear tendency to significance (p=0.052), a clear trend (p<0.09), a clear, strong trend (p=0.09), a considerable trend toward significance (p=0.069), a decreasing trend (p=0.09), a definite trend (p=0.08), a distinct trend toward significance (p=0.07), a favorable trend (p=0.09), a favourable statistical trend (p=0.09), a little significant (p<0.1), a margin at the edge of significance (p=0.0608), a marginal trend (p=0.09), a marginal trend toward significance (p=0.052), a marked trend (p=0.07), a mild trend (p<0.09), a moderate trend toward significance (p=0.068), a near-significant trend (p=0.07), a negative trend (p=0.09), a nonsignificant trend (p<0.1), a nonsignificant trend toward significance (p=0.1), a notable trend (p<0.1), a numerical increasing trend (p=0.09), a numerical trend (p=0.09), a positive trend (p=0.09), a possible trend (p=0.09), a possible trend toward significance (p=0.052), a pronounced trend (p=0.09), a reliable trend (p=0.058), a robust trend toward significance (p=0.0503), a significant trend (p=0.09), a slight slide towards significance (p<0.20), a slight tendency toward significance(p<0.08), a slight trend (p<0.09), a slight trend toward significance (p=0.098), a slightly increasing trend (p=0.09), a small trend (p=0.09), a statistical trend (p=0.09), a statistical trend toward significance (p=0.09), a strong tendency towards statistical significance (p=0.051), a strong trend (p=0.077), a strong trend toward significance (p=0.08), a substantial trend toward significance (p=0.068), a suggestive trend (p=0.06), a trend close to significance (p=0.08), a trend significance level (p=0.08), a trend that approached significance (p<0.06), a very slight trend toward significance (p=0.20), a weak trend (p=0.09), a weak trend toward significance (p=0.12), a worrying trend (p=0.07), all but significant (p=0.055), almost achieved significance (p=0-065), almost approached significance (p=0.065), almost attained significance (p<0.06), almost became significant (p=0.06), almost but not quite significant (p=0.06), almost clinically significant (p<0.10), almost insignificant (p>0.065), almost marginally significant (p>0.05), almost non-significant (p=0.083), almost reached statistical significance (p=0.06), almost significant (p=0.06), almost significant tendency (p=0.06), almost statistically significant (p=0.06), an adverse trend (p=0.10), an apparent trend (p=0.286), an associative trend (p=0.09), an elevated trend (p<0.05), an encouraging trend (p<0.1), an established trend (p<0.10), an evident trend (p=0.13), an expected trend (p=0.08), an important trend (p=0.066), an increasing trend (p<0.09), an interesting trend (p=0.1), an inverse trend toward significance (p=0.06), an observed trend (p=0.06), an obvious trend (p=0.06), an overall trend (p=0.2), an unexpected trend (p=0.09), an unexplained trend (p=0.09), an unfavorable trend (p<0.10), appeared to be marginally significant (p<0.10), approached acceptable levels of statistical significance (p=0.054), approached but did not quite achieve significance (p>0.05), approached but fell short of significance (p=0.07), approached conventional levels of significance (p<0.10), approached near significance (p=0.06), approached our criterion of significance (p>0.08), approached significant (p=0.11), approached the borderline of significance (p=0.07), approached the level of significance (p=0.09), approached trend levels of significance (p>0.05), approached, but did reach, significance (p=0.065), approaches but fails to achieve a customary level of statistical significance (p=0.154), approaches statistical significance (p>0.06), approaching a level of significance (p=0.089), approaching an acceptable significance level (p=0.056), approaching borderline significance (p=0.08), approaching borderline statistical significance (p=0.07), approaching but not reaching significance (p=0.53), approaching clinical significance (p=0.07), approaching close to significance (p<0.1), approaching conventional significance levels (p=0.06), approaching conventional statistical significance (p=0.06), approaching formal significance (p=0.1052), approaching independent prognostic significance (p=0.08), approaching marginal levels of significance p<0.107), approaching marginal significance (p=0.064), approaching more closely significance (p=0.06), approaching our preset significance level (p=0.076), approaching prognostic significance (p=0.052), approaching significance (p=0.09), approaching the traditional significance level (p=0.06), approaching to statistical significance (p=0.075), approaching, although not reaching, significance (p=0.08), approaching, but not reaching, significance (p<0.09), approximately significant (p=0.053), approximating significance (p=0.09), arguably significant (p=0.07), as good as significant (p=0.0502), at the brink of significance (p=0.06), at the cusp of significance (p=0.06), at the edge of significance (p=0.055), at the limit of significance (p=0.054), at the limits of significance (p=0.053), at the margin of significance (p=0.056), at the margin of statistical significance (p<0.07), at the verge of significance (p=0.058), at the very edge of significance (p=0.053), barely below the level of significance (p=0.06), barely escaped statistical significance (p=0.07), barely escapes being statistically significant at the 5% risk level (0.1>p>0.05), barely failed to attain statistical significance (p=0.067), barely fails to attain statistical significance at conventional levels (p<0.10), barely insignificant (p=0.075), barely missed statistical significance (p=0.051), barely missed the commonly acceptable significance level (p<0.053), barely outside the range of significance (p=0.06), barely significant (p=0.07), below (but verging on) the statistical significant level (p>0.05), better trends of improvement (p=0.056), bordered on a statistically significant value (p=0.06), bordered on being significant (p>0.07), bordered on being statistically significant (p=0.0502), bordered on but was not less than the accepted level of significance (p>0.05), bordered on significant (p=0.09), borderline conventional significance (p=0.051), borderline level of statistical significance (p=0.053), borderline significant (p=0.09), borderline significant trends (p=0.099), close to a marginally significant level (p=0.06), close to being significant (p=0.06), close to being statistically significant (p=0.055), close to borderline significance (p=0.072), close to the boundary of significance (p=0.06), close to the level of significance (p=0.07), close to the limit of significance (p=0.17), close to the margin of significance (p=0.055), close to the margin of statistical significance (p=0.075), closely approaches the brink of significance (p=0.07), closely approaches the statistical significance (p=0.0669), closely approximating significance (p>0.05), closely not significant (p=0.06), closely significant (p=0.058), close-to-significant (p=0.09), did not achieve conventional threshold levels of statistical significance (p=0.08), did not exceed the conventional level of statistical significance (p<0.08), did not quite achieve acceptable levels of statistical significance (p=0.054), did not quite achieve significance (p=0.076), did not quite achieve the conventional levels of significance (p=0.052), did not quite achieve the threshold for statistical significance (p=0.08), did not quite attain conventional levels of significance (p=0.07), did not quite reach a statistically significant level (p=0.108), did not quite reach conventional levels of statistical significance (p=0.079), did not quite reach statistical significance (p=0.063), did not reach the traditional level of significance (p=0.10), did not reach the usually accepted level of clinical significance (p=0.07), difference was apparent (p=0.07), direction heading towards significance (p=0.10), does not appear to be sufficiently significant (p>0.05), does not narrowly reach statistical significance (p=0.06), does not reach the conventional significance level (p=0.098), effectively significant (p=0.051), equivocal significance (p=0.06), essentially significant (p=0.10), extremely close to significance (p=0.07), failed to reach significance on this occasion (p=0.09), failed to reach statistical significance (p=0.06), fairly close to significance (p=0.065), fairly significant (p=0.09), falls just short of standard levels of statistical significance (p=0.06), fell (just) short of significance (p=0.08), fell barely short of significance (p=0.08), fell just short of significance (p=0.07), fell just short of statistical significance (p=0.12), fell just short of the traditional definition of statistical significance (p=0.051), fell marginally short of significance (p=0.07), fell narrowly short of significance (p=0.0623), fell only marginally short of significance (p=0.0879), fell only short of significance (p=0.06), fell short of significance (p=0.07), fell slightly short of significance (p>0.0167), fell somewhat short of significance (p=0.138), felt short of significance (p=0.07), flirting with conventional levels of significance (p>0.1), heading towards significance (p=0.086), highly significant (p=0.09), hint of significance (p>0.05), hovered around significance (p = 0.061), hovered at nearly a significant level (p=0.058), hovering closer to statistical significance (p=0.076), hovers on the brink of significance (p=0.055), in the edge of significance (p=0.059), in the verge of significance (p=0.06), inconclusively significant (p=0.070), indeterminate significance (p=0.08), indicative significance (p=0.08), is just outside the conventional levels of significance, just about significant (p=0.051), just above the arbitrary level of significance (p=0.07), just above the margin of significance (p=0.053), just at the conventional level of significance (p=0.05001), just barely below the level of significance (p=0.06), just barely failed to reach significance (p<0.06), just barely insignificant (p=0.11), just barely statistically significant (p=0.054), just beyond significance (p=0.06), just borderline significant (p=0.058), just escaped significance (p=0.07), just failed significance (p=0.057), just failed to be significant (p=0.072), just failed to reach statistical significance (p=0.06), just failing to reach statistical significance (p=0.06), just fails to reach conventional levels of statistical significance (p=0.07), just lacked significance (p=0.053), just marginally significant (p=0.0562), just missed being statistically significant (p=0.06), just missing significance (p=0.07), just on the verge of significance (p=0.06), just outside accepted levels of significance (p=0.06), just outside levels of significance (p<0.08), just outside the bounds of significance (p=0.06), just outside the conventional levels of significance (p=0.1076), just outside the level of significance (p=0.0683), just outside the limits of significance (p=0.06), just outside the traditional bounds of significance (p=0.06), just over the limits of statistical significance (p=0.06), just short of significance (p=0.07), just shy of significance (p=0.053), just skirting the boundary of significance (p=0.052), just tendentially significant (p=0.056), just tottering on the brink of significance at the 0.05 level, just very slightly missed the significance level (p=0.086), leaning towards significance (p=0.15), leaning towards statistical significance (p=0.06), likely to be significant (p=0.054), loosely significant (p=0.10), marginal significance (p=0.07), marginally and negatively significant (p=0.08), marginally insignificant (p=0.08), marginally nonsignificant (p=0.096), marginally outside the level of significance, marginally significant (p>=0.1), marginally significant tendency (p=0.08), marginally statistically significant (p=0.08), may not be significant (p=0.06), medium level of significance (p=0.051), mildly significant (p=0.07), missed narrowly statistical significance (p=0.054), moderately significant (p>0.11), modestly significant (p=0.09), narrowly avoided significance (p=0.052), narrowly eluded statistical significance (p=0.0789), narrowly escaped significance (p=0.08), narrowly evaded statistical significance (p>0.05), narrowly failed significance (p=0.054), narrowly missed achieving significance (p=0.055), narrowly missed overall significance (p=0.06), narrowly missed significance (p=0.051), narrowly missed standard significance levels (p<0.07), narrowly missed the significance level (p=0.07), narrowly missing conventional significance (p=0.054), near limit significance (p=0.073), near miss of statistical significance (p>0.1), near nominal significance (p=0.064), near significance (p=0.07), near to statistical significance (p=0.056), near/possible significance(p=0.0661), near-borderline significance (p=0.10), near-certain significance (p=0.07), nearing significance (p<0.051), nearly acceptable level of significance (p=0.06), nearly approaches statistical significance (p=0.079), nearly borderline significance (p=0.052), nearly negatively significant (p<0.1), nearly positively significant (p=0.063), nearly reached a significant level (p=0.07), nearly reaching the level of significance (p<0.06), nearly significant (p=0.06), nearly significant tendency (p=0.06), nearly, but not quite significant (p>0.06), near-marginal significance (p=0.18), near-significant (p=0.09), near-to-significance (p=0.093), near-trend significance (p=0.11), nominally significant (p=0.08), non-insignificant result (p=0.500), non-significant in the statistical sense (p>0.05), not absolutely significant but very probably so (p>0.05), not as significant (p=0.06), not clearly significant (p=0.08), not completely significant (p=0.07), not completely statistically significant (p=0.0811), not conventionally significant (p=0.089) but..., not currently significant (p=0.06), not decisively significant (p=0.106), not entirely significant (p=0.10), not especially significant (p>0.05), not exactly significant (p=0.052), not extremely significant (p<0.06), not formally significant (p=0.06), not fully significant (p=0.085), not globally significant (p=0.11), not highly significant (p=0.089), not insignificant (p=0.056), not markedly significant (p=0.06), not moderately significant (p>0.20), not non-significant (p>0.1), not numerically significant (p>0.05), not obviously significant (p>0.3), not overly significant (p>0.08), not quite borderline significance (p>=0.089), not quite reach the level of significance (p=0.07), not quite significant (p=0.118), not quite within the conventional bounds of statistical significance (p=0.12), not reliably significant (p=0.091), not remarkably significant (p=0.236), not significant by common standards (p=0.099), not significant by conventional standards (p=0.10), not significant by traditional standards (p<0.1), not significant in the formal statistical sense (p=0.08), not significant in the narrow sense of the word (p=0.29), not significant in the normally accepted statistical sense (p=0.064), not significantly significant but..clinically meaningful (p=0.072), not statistically quite significant (p<0.06), not strictly significant (p=0.06), not strictly speaking significant (p=0.057), not technically significant (p=0.06), not that significant (p=0.08), not to an extent that was fully statistically significant (p=0.06), not too distant from statistical significance at the 10% level, not too far from significant at the 10% level, not totally significant (p=0.09), not unequivocally significant (p=0.055), not very definitely significant (p=0.08), not very definitely significant from the statistical point of view (p=0.08), not very far from significance (p<0.092), not very significant (p=0.1), not very statistically significant (p=0.10), not wholly significant (p>0.1), not yet significant (p=0.09), not strongly significant (p=0.08), noticeably significant (p=0.055), on the border of significance (p=0.063), on the borderline of significance (p=0.0699), on the borderlines of significance (p=0.08), on the boundaries of significance (p=0.056), on the boundary of significance (p=0.055), on the brink of significance (p=0.052), on the cusp of conventional statistical significance (p=0.054), on the cusp of significance (p=0.058), on the edge of significance (p>0.08), on the limit to significant (p=0.06), on the margin of significance (p=0.051), on the threshold of significance (p=0.059), on the verge of significance (p=0.053), on the very borderline of significance (0.05
But, it raises two points. First, if you're criticizing for this practice, note that that contradicts the "P-values are only interpreted as significant/not significant" charge. Second, consider the dozens of just as silly names for Bayesian priors:

- P-values are only interpreted as significant/not significant Note that this criticism contradicts the "silly labels for p-values" charge. P-values can also be interpreted using a spectrum (which of course depends on α too). Consider the following p-value graphic from The Statistical Sleuth: A Course in Methods of Data Analysis
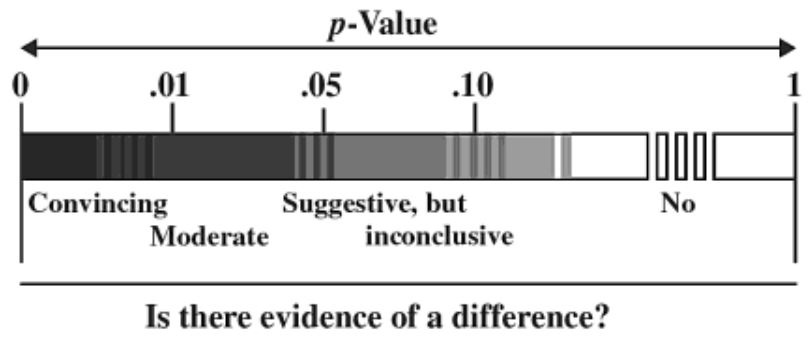
Also, consider the following Bayes factor range interpretations from a study:
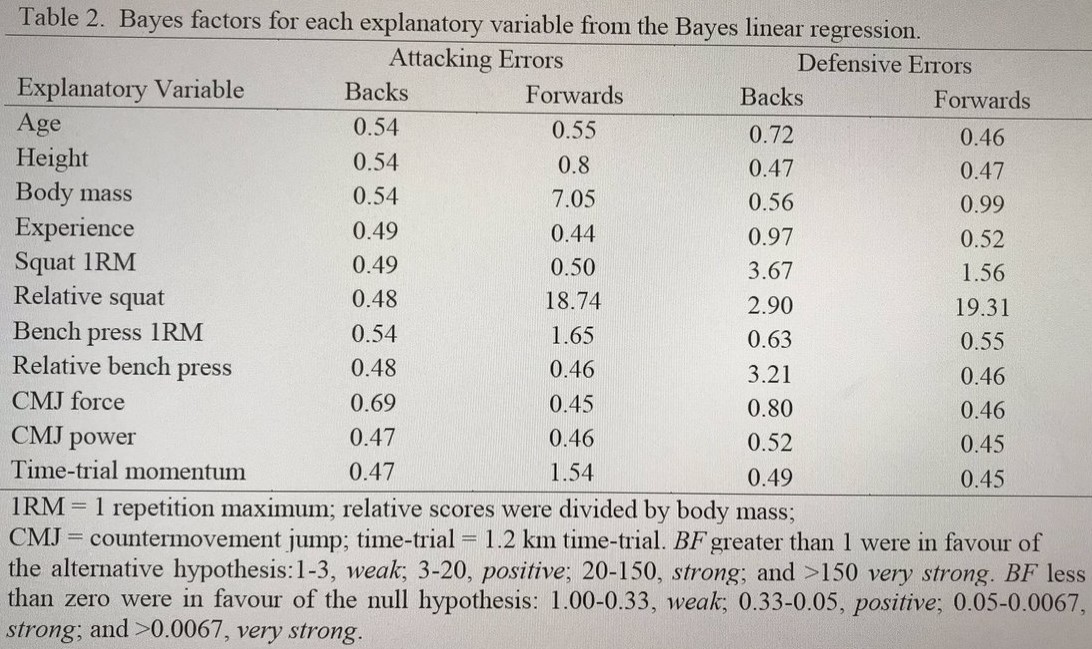
The Bayes factors could also be interpreted just using a strong/weak dichotomy if a researcher wanted to. In summary, the type of statistic is not the issue. The issue is those choosing a rigid cutoff for an interpretation, which is not necessarily automatically a bad thing.
- Everyone is critical of NHST From Will the ASA's Efforts to Improve Statistical Practice be Successful? Some Evidence
to the Contrary, by Hubbard (slightly modified)
YearsCitations Critical of NHST% using NHST in social science% using NHST in management sciences1960-19697256521970-197961672801980-19891,60384691990-19994,73792922000-200910,88492932010-201714,448--1960-201732,360--
First, this pattern is probably similar in all sciences and topics that use statistics. Second, are we really to believe that it is so difficult and flawed, yet it is so widely adopted? Or is it more likely that in the publish or perish world, academics are vying for grant money and journal real estate using the cottage industry of critiquing successful but imperfect approaches (NHST, frequentism, etc.) to discuss their pet alternatives? I think the latter is very much more likely.
Also, please read In Praise of the Null Hypothesis Statistical Test, by Hagen. A sampling of some things he writes
"The NHST is not embarrassed by demonstrations that Type I errors can be produced given a large number of replications."
...
"The logic of the NHST is elegant, extraordinarily creative, and deeply embedded in our methods of statistical inference."
...
"It is unlikely that we will ever be able to divorce ourselves from that logic even if someday we decide that we want to."
...
"...the NHST has been misinterpreted and misused for decades. This is our fault, not the fault of NHST. I have tried to point out that the NHST has been unfairly maligned; that it does, indeed, give us useful information; and that the logic underlying statistical significance testing has not yet been successfully challenged."In Confessions of a p-value lover, Adams, an epidemiologist, dissects popular criticisms of p-values and NHST using a refreshing commonsense approach. Adams writes
"They [p-values] have helped me interpret findings, determine which scientific leads to follow-up on, and which results are likely not worth the time and effort."
...
"The authors [critics] call for embracing uncertainty, but fail to see that research is done to achieve exactly the opposite: we want to be as informed as possible when making yes/no scientific and policy decisions."
...
"While the scaremongering around NHST suggests so, in fact no healthcare policy has ever been based on a mere glance at whether p<0.05."
...
"The authors argue that NHST should be banned to solve these problems, except for "specialized" situations - a caveat that will immediately make a careful reader question whether NHST is truly the cause of the problem. If some situations warrant NHST, then clearly NHST should not be blindly banned."
...
"Inadvertently, the authors have themselves stumbled upon yet another misuse of p-values and NHST: as a scapegoat for statistical malpractice." - Frequentists use randomness to avoid dealing with hard problems
Modern science can use randomization to make inferences of cause and effect and infer from samples to
populations. Just these two examples have revolutionized science and our understanding of the world. One can also use randomness in spicing up exercise
routines, overcoming boredom, choosing a restaurant to eat out at, making flash cards for studying
any topic, revitalizing chess with
randomized starting positions, casinos, lotteries, making fair decisions, making scatterplots more
readable by jittering, making video game experiences different with each play, generating strong
passwords, shuffling the music you listen to, in endeavors such as poetry and art, and on and on.
Random numbers play a huge role in modern life. See The
Drunkard's Walk: How Randomness Rules Our Lives by Mlodinow.
I would opine that the complaint "frequentists use randomness to avoid dealing with hard problems" is really the compliment "frequentists use sampling to intelligently solve hard problems".
- The American Statistical Association (ASA) wrote a document against p-values It is important to correct critics' misinformation, over and over again, that the ASA report is not anti p-values, but is only saying to not use a p-value, or any other single measure, as the only deciding factor in an analysis. Here is a quote from a critic as the type of misinformation I am speaking about:

As mentioned, this particular ASA document was not against p-values but against the misunderstanding and misuse of p-values. In that document they wrote that other approaches, like Bayesian, "...have further assumptions". I was always taught to not just do p < .05 and leave it at that, but to have good experimental or survey design, give confidence intervals, graphs, not have arbitrary cutoffs, and so on. See Regarding the ASA Statement on P-Values and The Statistical Sleuth by Ramsey and Schafer. Mayo writes
"Misinterpretations and abuses of tests, warned against by the very founders of the tools, shouldn't be the basis for supplanting them with methods unable or less able to assess, control, and alert us to erroneous interpretations of data."
By the way, these warnings about p-values are all things that we have known since Fisher's time. For example Stigler notes "Even in the 19th century, we find people such as Francis Edgeworth taking values 'like' 5% - namely 1%, 3.25%, or 7% - as a criterion for how firm evidence should be before considering a matter seriously". This is before Fisher's time.
- Banning significance testing and terminology In 2019, the ASA and Nature published (hit?) pieces on mainstream statistical inference. They mention the dangers of "dichotomania", but tended to throw the error control baby out with the misuse bath water. In all those writings, no real good alternatives were given, their pros/cons discussed in detail, nor were the many good things done using significance testing (in over 70+ years of science and other disciplines all over the world) discussed. See ASA's Statistical Inference in the 21st Century: A World Beyond p < 0.05, and Nature's Scientists rise up against statistical significance. Critics seem to be confused why articles in Nature and ASA publications using "p<" and statistical significance terminology are already appearing after the publication of the pieces.
What was the effect of this ASA publication? With the confusion created in their 2019 publication, I believe ASA jumped the statistical shark.
Macnaughton has a website The War on Statistical Significance, and a book The War on Statistical Significance: The American Statistician vs. the New England Journal of Medicine. In a JSM 2021 presentation he concluded that
"The current war on statistical significance, though well intentioned, is misguided, because it recommends that we abandon a system that helps to maximize the overall benefit of scientific research. ... Statistical significance helps maximize the benefit by sensibly balancing the long-run rates of costly false-positive and false-negative errors in scientific journals."
He noted that this notion applies to all other correlated measures of weight of evidence such as t-statistic, confidence interval, likelihood ratio, Bayes factor, second-generation p-value, posterior probability, and some others.
In Statistical significance gives bias a free pass by Amrhein et al, they say that
"A major consequence is flip-flopping headlines such as 'chocolate is good for you' followed by 'chocolate is bad for you'. No wonder only about a third of over 2000 respondents in a survey on the British public said they would trust data from medical trials."
Using public misunderstanding of 'chocolate is good for you' vs. 'chocolate is now bad for you' studies is silly. First, frequentist methods allow for error and Bayesian methods would not solve this issue either. Second, is there an issue if the studies are of different quality? Third, they oddly use results from a frequentist survey to argue their point. Fourth, the quality of BASP articles declined after these things were banned, as well as p-values are used in Nobel prize winning work and also in analyzing quantum supremacy data. Last, a meta analysis of studies would be more reliable than any individual study. We should teach the public these things instead of the boogeyman of 'flip flopping' results.
Another way of looking at "dichotomania", is from An Investigation of the Laws of Thought by Boole. He wrote that X2=X, or X(1-X)=0, where X is a set and the operations are set operations, is the fundamental "law of thought". That is, something cannot be in both sets X and 1-X at the same time. Boole used this law to compute probabilities and statistics. Boole's work was modernized and made rigorous by Hailperin in Boole's Logic and Probability: Critical Exposition from the Standpoint of Contemporary Algebra, Logic and Probability Theory in a linear programming context. Also check out The Last Challenge Problem: George Boole's Theory of Probability by Miller.
- alternatives to the p-value See The practical alternative to the p-value is the correctly used p-value by Lakens
There are many proposed other "pet alternatives" to p-values, but what is their acceptance and performance in scientific and other areas all over the world? With p-values we already have this, but other approaches are unproven.
The scientific use of the word "work" (force in the direction of motion multipled by a distance) is different from the everyday use of the word "work" (sitting at a computer and reading?), yet many criticisms against "confidence" in "confidence interval" that want to replace it with "compatibility" or something else, make that very critique. Of course, the same critique against "confidence" could be could be said about "prior" or "surprise", or just about anything else.
Greenland et al in Semantic and cognitive tools to aid statistical science: replace confidence and significance by compatibility and surprise argue that using an information type of measure like s = -logbase 2(p-value), or s = -log(p-value)/log(2), which can be interpreted as bits of information against H0, or the number of heads observed in as many flips of a coin, to measure "surprisal", is better than using a p-value, namely because large values reject H0, it may be more intuitive, is on a better scale, etc. While I do sincerely appreciate comparing things to coin flip experiments, I don't find their reasoning too compelling. We are currently already going from raw data to summaries like means and SDs to standardized values like z-scores, and finally p-values. Now we add another step and look at a transformation of the p-value? It is claimed elsewhere that this is defining surprise based on a "parasitic" definition that treats probability as coming first, and that probability can be defined by treating surprisal as fundamental, by p = e-s. However, we know from history that probability, in fact, did come first (see Games, Gods And Gambling: The Origins And History Of Probability And Statistical Ideas From The Earliest Times To The Newtonian Era by Florence Nightingale David), and information approaches arrived later.
I'm also not sure I think bits is as intuitive as they suggest. Winning the lottery is about 24 bits of surprisal, but that is not as intuitive to me as a really small probability. I read that writing 24 is more manageable than writing out a really small probability, but we can just write really small probabilities using scientific notation. Probability is already a fairly natural scale, can be interpreted as frequencies ("X times out of 100, on average this occurs"), and small p-values already correspond to large values of your test statistic. If you want something intuitive and on a good scale, one can just use the observed data. Also, differences in probabilities make intuitive sense in a frequency interpretation. A difference between say of 1.301 and 1.221 bits means what exactly, fractional information? They also discuss being able to combine s values, but p-values can already be combined. That probabilities are compressed in [0,1] they use as a critique, yet probabilities for events sum to 1, something that does not happen with s values. In short, every criticism of probabilities can be turned around as a plus for probabilities compared to s values, in my opinion.
Greenland et al in Technical Issues in the Interpretation of S-values and Their Relation to Other Information Measures have also characterized "severity" (see Statistical Inference as Severe Testing: How to Get Beyond the Statistics Wars by Mayo) as just being the p-value curve. I believe it is more accurate to say severity is more like attained power. But also note that the philosophy and science is different with severity as compared to standard interpretations and also compared to proposed alternatives like s, because severity is more about seeing if a claim is well-tested, not just a probability or being surprised.
- Effect of the ban in Basic and Applied Social Psychology (BASP) What were the effects after BASP banned the use of inferential statistics in 2015? Did science improve? Sensible questions. Ricker et al in Assessing the Statistical Analyses Used in Basic and Applied Social Psychology After Their p-Value Ban write
In this article, we assess the 31 articles published in Basic and Applied Social Psychology (BASP) in 2016, which is one full year after the BASP editors banned the use of inferential statistics.... We found multiple instances of authors overstating conclusions beyond what the data would support if statistical significance had been considered. Readers would be largely unable to recognize this because the necessary information to do so was not readily available.
Also, please read So you banned p-values, how's that working out for you? by Lakens.In Dear p-values, it's not me, it's not you, it's everyone else Adrian Barnett pledges "There will be no p-values in any paper that I co-author in the next 12 months." That did not work too well when BASP tried it. Actually, what will happen with those that refuse to use p-values in papers, is that they will most likely use p-values behind the scenes to assess the distance between what is observed and what is expected under the model. If they use some alternative, the onus is on them to show it works and to discuss any limitations of the alternative.
Additionally, Trustworthiness of statistical inference by Hand, notes problems with the BASP proposal to ban null hypothesis significance testing.
- Experiments Frequentism lends itself to experiments really well. It is especially good at discovering probabilities. See Flipping Tacks, Probability of finding Money, How Many Cars Have Old Antennas?, and Probability of finding Sticks for Self Defense.
- History The book Games, Gods And Gambling: The Origins And History Of Probability And Statistical Ideas From The Earliest Times To The Newtonian Era by Florence Nightingale David, explains how the origins of probability and statistics were based on games of chance with simple frequency interpretations. Because the origin of probability was based on frequency concepts, one can fairly conclude frequency concepts are natural.
- Lindley said the future is Bayesian He was a great statistician (understatement), but this might be wishful thinking. For example, it is known (now?) that Bayesian is "brittle". See On the Brittleness of Bayesian Inference by Owhadi, Scovel, and Sullivan and Qualitative Robustness in Bayesian Inference by Owhadi and Scovel. Also, Judea Pearl does not think Bayesian is good for causality (presumably he does not think frequentism is either) See Bayesianism and Causality, or, Why I am Only a Half-Bayesian. Pearl has also said "In my opinion, BDA [Bayesian Data Analysis - J] is a siren song that lures people away from properly 'thinking' about causation..." as well as "Bayesians find it harder to understand causality than frequentists.". Lindley said that "We will all be Bayesians in 2020, and then we can be a united profession.", and he will be wrong, mainly because frequentism is logical and useful.
- Maximum likelihood estimation is also "brittle" because it does not provide the full picture of the parameter surface. You might just be getting a full picture of your beliefs, which might not be too useful because Bayesian is brittle as already discussed. The term "brittle" here refers to a specific mathematical definition. See On the Brittleness of Bayesian Inference by Owhadi, Scovel, and Sullivan. Additionally, frequentists can use more than just maximum likelihood estimation, for example, method of moments, bootstrapping, permutations, lasso, ridge, etc.
- Bayesian is the new probability and statistics, replacing the old frequentism style of probability and statistics Actually, most people used to be Bayesian (Laplacian!) until results (as in, getting results) from frequentism took over in science. Bayesian is making a comeback due to computation being better now. Bayesian statistics is now a "pop culture" thing, being rediscovered and popularized mostly in communities outside of statistics proper, like AI/machine learning, etc.
- Everyone should be Bayesian See Efron's Why Isn't Everyone a Bayesian and Bayes Theorem in the Twenty-first Century. Also see Senn's You May Believe You Are a Bayesian But You Are Probably Wrong. Also, Mayo details that Gelman has made the remark that a Bayesian wants everybody else to be a non-Bayesian That way, he wouldn't have to divide out others' priors before he does his own Bayesian analysis.
- Sherlock Holmes was Bayesian! And therefore you should be too. I do not believe Holmes was Bayesian (who cares since he is fictional?), but let's look at some things Holmes said
- "How often have I said to you that when you have eliminated the impossible, whatever remains, however improbable, must be the truth?", and similiar variations
- "We balance probabilities and choose the most likely. It is the scientific use of the imagination."
- "while the individual man is an insoluble puzzle, in the aggregate he becomes a mathematical certainty. You can, for example, never foretell what any one man will do, but you can say with precision what an average number will be up to. Individuals vary, but percentages remain constant. So says the statistician."
- "Data! Data! Data! I can't make bricks without clay."
- "One should always look for a possible alternative, and provide against it."
- "It is certainly ten to one that they go downstream, but we cannot be certain."
- "It's life or death - a hundred chances on death to one on life."
- "Dirty-looking rascals, but I suppose every one has some little immortal spark concealed about him. You would not think it, to look at them. There is no a priori probability about it. A strange enigma is man!"
- Also, in "The Adventures of the Dancing Men", Holmes broke essentially a substitution code using a frequentist solution.
I believe these instances show Holmes using concepts from frequentist, likelihood, and Bayesian schools of thought.
- Bayesian credible interval interpretation is more natural, and it is what everyone using frequentist confidence intervals wants to say anyway. It is much easier to say
"the probability μ is in the interval is 80%" than to reason "if we repeated this process X times, the true μ would be in 80% of the intervals", but it may not be correct, since your credible interval can be strongly influenced by subjective beliefs, and the "probability" Bayesians talk about may not be probability as properly defined but rather "chance", "uncertainty", or "personal belief". In science, we are interested in replication and objectivity, which the frequentist confidence interval gives a nod to.
One could argue the other way, that Bayesians really want to say that their procedures have good long-term performance, good coverage, be free from as much subjectivity as possible, or not be confined to having to try and solve all problems with the same tool.
This "what we really want to know (or say), is X" has been called "The Statistician's Fallacy" by Lakens. That is, statisticians saying what all researchers supposedly want to know, and not coincidentally the answer X is aligned 100% with the statistician's philosophy of statistics and science.
- Bayesian credible intervals give us everything we want Actually, they tend to be reliant on a prior. In Coherent Frequentism: A Decision Theory Based on Confidence Sets by Bickel, he says
Viewed from another angle, the fact that close matching can require resorting to priors that change with each new observation, cracking the foundations of Bayesian inference, raises the question of whether many of the goals motivating the search for an objective posterior can be achieved apart from Bayes's formula. It will, in fact, be seen that such a probability distribution lies dormant in nested confidence intervals, securing the above benefits of interpretation and coherence without matching priors, provided that the confidence intervals are constructed to yield reasonable inferences about the value of the parameter for each sample from the available information. ... In conclusion, the multilevel or level of confidence in a given hypothesis has the internal coherence of the Bayesian posterior or class of such posteriors without requiring a prior distribution or even an exact confidence set estimator. More can be said if the parameter of interest is one dimensional, in which case the confidence level of a composite hypothesis is consistent as an estimate of whether that hypothesis is true, whereas neither the Bayesian posterior probability nor the p-value is generally consistent in that sense.
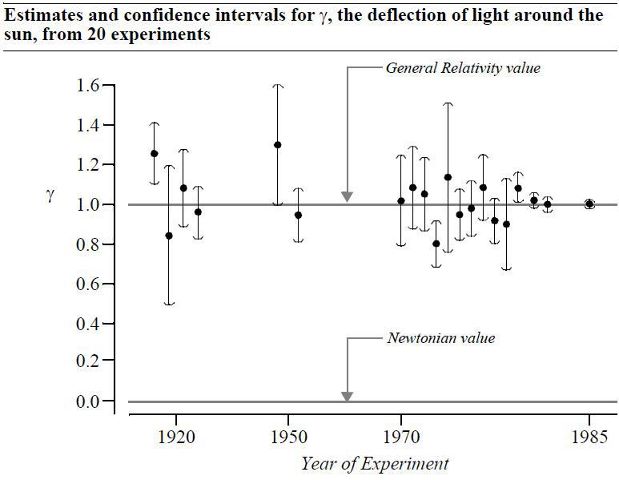
- Everyone really wants to calculate P(H0 true). Frequentists cannot do this but try to with their p-value, but Bayesians can. Actually, most people, Bayesians or frequentists, probably agree that a hypothesis is either true or false, and that we use probability to inform us in some way. Some might say that the probability of a null hypothesis is 0 since it asks for the probability of something equalling a continuous number. I'd opine that while Bayesians can turn the mathematical crank and produce something they label P(H0 true), that they are still not calculating P(H0 true), but only P(H0 true | subjective beliefs). Because the definition of probability is a long-term frequency, rather than a subjective belief, the Bayesian P(H0 true) may not be convincing. Second, frequentists can get at something like a P(H0 true), if they'd even want to, by considering the ratio (number of experiments that fail to reject H0 / number of experiments over time). For example, using the results from the deflection of light experiments above, we get something like

This "hits you between the eyes" that H0 is probably true. This is because the ratio is large, the experiments are well-designed, and there are many experiments, not just 1 or 2. No approach will ever logically prove H0 is true, but only supply evidence for or against.
Regarding the claim "everyone really wants P(H0|data)", even conceding this point to be true for sake of argument, one realizes after some thought that one only gets this if they allow subjective probabilities to enter, so they can't really ever get this. Therefore, one has to instead focus on P(data|H0) and use modus tollens logic. People confusing one probability with the other is the "error of the transposed conditional". However, frequentists are not confusing one with the other. The following is a common cute critique against P(data|H0)

However, critics are missing the crucial fact that "null hypothesis is true" is about the population. They are also missing the fact that Bayesians cannot get at P(H0|data) either but only at P(H0|data, my subjective beliefs), which is not the same thing.
Additionally, a null hypothesis doesn't have to be a nil hypothesis. That is, one doesn't have to test against 0, but can test any value or a range of values. However, the popular refrain that an effect can never actually equal 0, is that in any one study the effect will probably never equal exactly zero, but there is may be little reason to disbelieve that these discrepancies will not even out across studies, leaving the null hypothesis of a 0 effect true at the level of the population.
- Frequentism is too indirect. Direct statements are better.
The logic of modus tollens (MT) says P->Q, and if we observe not Q, therefore we conclude not P. Note that P is the null hypothesis H0, and Q is what we'd expect the test statistic T to be under H0. A concrete example is, we agree on assuming a fair coin model. We therefore expect about 50 heads if we flip a coin 100 times. However, we observe 96 heads (96 put on a p-value scale would be an extremely small p-value). Therefore, we conclude the fair coin model is not good. This type of logical argument is valid and essential for falsification and good science a la Popper.
A critic has said that "p-values are the degree of embarrassment of the null hypothesis by the data". However, "embarrassment" is a subjective and emotional term, not a mathematical one. As mentioned, p-values are calculated in part from summaries of observations (ie. the evidence), and are just the rescaled distance what you observed is from what is expected under the model. Model, assumptions, CIs, etc. also get reported in most analyses, not just p-values.
- Modus tollens (MT) is false when put in probability terms No. It is still valid, but we of course always have risk when making decisions based on data. Modus tollens and modus ponens logic put in terms of probability effectively introduce bounds, much like in linear programming. See Boole's Logic and Probability by Hailperin, and Modus Tollens Probabilized by Wagner.
- With modus tollens, all frequentists can really say is: If "null true" then Q = "p-value in U(0,1)", then we observe p-value in [0,1], and therefore...what exactly? Actually, this critic is misunderstanding how proof by contradiction works. We don't observe any old p-value in (0,1) in order to reject H0, we observe a very small p-value, and the p-value is tied to evidence. For example, flipping a coin 100 times, we expect Q = 50 heads assuming a fair coin model. His step 2 in his logic would be more like we've observed 98 heads and p << .0001, which is evidence to reject H0. Note that I am not saying "prove" or "there is a real effect", etc. In real life, we'd try to repeat the experiment several times and note the p-values before thinking of declaring anything real or not. The p-value won't be "equally in (0,1)" if the null is false, that's the point. Surely any critic can understand that if the coin was fair, it would be extremely unlikely to get say around 95 heads in 100 flips in each of, say, 5 experiments. If we did but they maintained they had a reasonable explanation for why the coin really is fair, even after this overwhelming evidence it is not fair, I'd love to hear it.
- Bayesian deals with nuisance factors easier Note this contradicts the "frequentists don't want to deal with hard math" charge. Nuisance
parameters are a
nuisanceproblem for statistics based on profile likelihood ratios, but the distribution can become independent of the nuisance parameters in the limit. - Multiple testing is confusing, and the outcome shouldn't depend on the number of comparisons However, recognizing and adjusting for multiple comparisons is in line with good understanding of probability and science. Note, this contradicts "a lot of experiments leads to spurious results" and contradicts the "frequentists don't want to deal with hard math" charges. Because frequentists are often willing to adjust α, it also slightly contradicts the "using α=.05 is arbitrary" charge.
Frequentism relies on data you didn't observe.
- Strong Law of Large Numbers (SLLN) requires infinity Actually, finite versions of laws of large numbers exist. See The Laws of Large Numbers Compared by Verhoeff. Also, consider the argument of agreeing upon using an n much less than infinity. Let's just agree on using n = 1,000,000. Do you truly believe you wouldn't learn a lot about a coin (phenomenon, claim) from that many flips (experiments, trials)? Paradoxically, critics saying "Oh, but the scientist could have used a different analysis than the frequentist one they used!' to try and diminish frequentism is itself appealing to things that could have been done, but weren't.
- Sample space, hypothetical repeated experiments is bad, nonsensical, etc
We literally learn by sampling from the world. Also, if you obtained one or a few samples, it is not outrageous to suggest you
can get another sample. There are many sample surveys, for example, that have been going on for a long time, and many that are not only done every year, but every quarter, or and even every month. Simulation, Monte Carlo, and bootstrap are done in science all the time, but this is not actually observed data. Counterfactuals are also used, and even essential, in studying causality. See The Book of Why: The New Science of Cause and Effect and Causal Inference in Statistics: A Primer and Causality: Models, Reasoning and Inference by Pearl, for the importance of counterfactual reasoning. Also, counterfactual reasoning is used in science, in the notion of severity and how well a claim has been probed. See Severe Testing as a Basic Concept in a Neyman-Pearson Philosophy of Induction by Mayo and Spanos and Statistical Inference as Severe Testing: How to Get Beyond the Statistics Wars by Mayo. The logic of subjunctive conditionals (ie. counterfactuals) is well developed.
Also, hypotheticals are used in Bayesian statistics often. For example, in prior predictive checks and especially posterior predictive checks. Betancourt has said
I recommend that you run as many replications as your computational resources allow
Posterior predictive checks have also been criticized as "using the data twice". Posterior predictive checks also violate the "likelihood principle" that Bayesians often critique frequentism about. Ideally, validation would be done on external data, on internal "hold out" data, or by cross-validatation. Posterior predictive checking and going back to tweak priors (a different type of "p-hacking") can encourage overfitting, overconfidence, and over-reliance on graphical checks which can be subjective. - Let's look at assumptions. Bayesian: Distributional + prior assumption. Frequentism: Distributional + sampling distribution assumption. You don't need a prior to be 'true', you need it to be defendable. "Given this prior uncertainty, what do the data suggest?" Can you defend the existence of a sampling distribution? How do you "defend the existence" of a subjective prior that can be anything you believe in your mind? There's a reason sampling distributions do not have a separate variety called "subjective" like priors do. Sampling distributions have to be tied to the real world via sampling, that is, they cannot just be anything.
- Bayesians can write down their prior while frequentists can't even write down their sample space One can write down the sample space say for N flips of a coin. Consider 1 flip, the sample space is S = {H,T}. Consider 2 flips, the sample space is S = {HH,TT,HT,TH}, etc. A computer does sample space enumeration easily. Consider the Monty Hall Let's Make a Deal problem. If we don't switch doors, the sample space is S = {(1,2,1,WIN), (1,3,1,WIN), (2,3,2,LOSE), (3,2,3,LOSE)}, and if we decide to switch doors, the sample space is S = {(2,3,1,WIN), (3,2,1,WIN), (1,2,3,LOSE), (1,3,2,LOSE)}. I do agree that writing down a sample space for difficult problems is...difficult, however. Note that this apparently contradicts the "frequentists don't want to deal with hard math" charge.
- Frequentist appeal to asymptotics is silly Actually, saying appealing to asymptotic results is silly is what is really silly. The Strong Law of Large Numbers (SLLN) and the Central Limit Theorem (CLT), for example, are some of the most important results in mathematical statistics. Approximations are a good thing, especially if the "exact" calculation doesn't differ much from the approximation. The CLT is a mathematical fact, and we see it work in simulations as well. There is also a "Bayesian CLT", the Bernstein-von Mises theorem. Obviously, just blindly applying asymptotics (or anything else) is not wise. Statisticians would need to simply make sure their sample size is large enough and check any and all assumptions (again, just like anything else) to be justified in using asymptotic theory.
Some critics have suggested that CLT has poor performance for say a lognormal population. However, if there was a lognormal population, a statistician would make a histogram and observe that it is skewed, and probably consider taking a transformation of the data, such as a log. The critic then says 'ah, but you can't do that' or 'but you don't know what transformation to take'. However, how can the critic even know the population is exactly lognormal to begin with? A statistician in real life would simply observe the skew, take a transform, then back-transform to get, for example, a confidence interval on the original non-transformed scale. But the critic would then say 'ah, but now this is an interval on the median, not the mean'. But the frequentist would then say that for skewed distributions like lognormal, they are often described by their median better than their mean, and moreover, equations exist for confidence intervals of their mean and median anyway. And on and on and on!
- Frequentism hypothesis testing requires H0 to be exactly true Nothing requires any model to be exactly true outside of the mathematics. If any assumptions do not hold exactly in reality, there are the fields of robust and nonparametric statistics which can address these issues.
- Frequentism hypothesis testing requires repeated experiments to be identical for the α level to make sense Again, no. Neyman wrote decades ago that because of the Central Limit Theorem, the mean of the experiment αs converge to the specified α level. This also holds for the (1-β)s, or powers, too.
- Frequentism confidence or prediction intervals don't reflect the uncertainty in the maximum likelihood estimates For some estimation methods this is true, however, there might be a tradeoff between that and using possibly subjective, brittle priors. However, the book Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort shows how to take the uncertainty in maximum likelihood estimates into account.
- Wear and tear on a coin from many flips, which alters the frequencies of heads and tails, means frequentism cannot work This argument could apply to any physical system. However, because the concept of probability still works in these cases, we conclude this "wear and tear alters probabilities drastically" argument is flawed. Clearly the miniscule amount of physical wear and tear is not big enough to influence probability. If it were when we were flipping a quarter, we'd simply chose a different quarter to flip at that time. This is related to the question of the long term behavior of dice and if more material scooped out of a face changes that side's frequency. The answer is technically yes, but not enough to matter in any practical way. Moreover, we can use a 'digital coin', with absolutely no wear and tear, as a useful model. If you think there is anything that influences a probability, you can always do an experiment to test for that. Clearly a Bayesian or any other approach to probability and statistics would also be dealing with wear and tear, which makes it a poor argument against frequentism.
Paradoxically, one wouldn't actually want experiments literally identical in every aspect in real life anyway (only want identical on the major things we can control). If that happened, your findings may only concern that exact experimental setup, but for inference we want to extend our results in a more general way.
- One-sided hypothesis tests are biased, have greater Type I error, contribute to the replication crisis, have more assumptions, are controversial, and etc. At OneSided.org, Georgiev addresses these unfair portrayals of one-sided hypothesis tests and many related topics. He writes
We publish articles explaining one-sided statistical tests, resolving paradoxes and proving the need for using one-sided tests of significance and confidence intervals when claims corresponding to directional hypotheses are made. There are interactive simulations and code for simulations you can run yourself. You will also find links to related literature: both for and against one-sided tests.
- Frequentism relies on "i.i.d." assumptions It is false to imply frequentism relies on i.i.d. assumptions for everything. Obviously a lot of theory and teaching is done using "i.i.d" assumptions, but then complexity increases from there. In fact, there are many examples in probability and statistics where the random variables are not independent but they are identically distributed, the random variables are independent but are not identically distributed, or the random variables are neither independent nor identically distributed. For example, some types of sampling, time series, and urn models are just a few examples.
- Bayesian statistics uses MCMC to solve problems Bayesian statistics often rely on frequentist concepts for support.
For example, the basic Bayes Rule is itself frequentist. In some forms of Bayesian statistics, prior distributions
often come from previous experiments. Also, sampling from the posterior distribution using Markov Chain Monte Carlo (MCMC) has a frequentist feeling about it. For example:
- Use a burn-in period? Make coin flips > some small number, since relative frequency is "rough" for a small number of flips.
- Use more iterations? Flip the coin more times, you know it will have a better chance of convergence.
- Use more chains? Flip more coins, multiple evidence of convergence is better evidence than few.
- Starting with a different seed? If it still converges with different seeds, this is like entering a "collective" randomly and still getting the same relative frequency.
In The Interplay of Bayesian and Frequentist Analysis by Bayarri and Berger, they say
...any MCMC method relies fundamentally on frequentist reasoning to do the computation. An MCMC method generates a sequence of simulated values θ1,θ2,...,θm of an unknown quantity θ, and then relies upon a law of large numbers or ergodic theorem (both frequentist) to assert that... Furthermore, diagnostics for MCMC convergence are almost universally based on frequentist tools.
In addition, Bayesian statistics regularly uses other frequentist concepts such as histograms, distributions, sampling, simulation, model checking, calibration, nonparametrics, and asymptotic procedures, to name a few.
- Priors Do Bayesians observe all values of a prior/posterior that has a continuous distribution or the thousands of realizations from a MCMC? If not, then they are using data they didn't actually observe.
Frequentism is bad for science.
- Frequentism is bad for science Bayesian claims of frequentism being bad for science, fail to mention the examples of frequentism being good for science, which is selective reporting. There are plenty of examples of frequentism being good, if not great, for science: survey sampling, polling,
quality control, Framingham Heart Study, studies showing smoking is bad for you, Rothamsted
Experimental Station experimental design, casinos, life insurance, weather prediction (NWS MOS),
lotteries, German tank problem, randomization, ecology, and Bayes Theorem itself is a frequentist
theorem.
I strongly believe that probability and statistics are the method of the scientific method. See the books The Lady Tasting Tea: How Statistics Revolutionized Science in the Twentieth Century by Salsburg, and Creating Modern Probability: Its Mathematics, Physics and Philosophy in Historical Perspective by von Plato. Also, see Frequentism is Good response to the "airport fallacy" article by Gunter and Tong that appeared in the 10/2017 issue of Significance, I say

"I agree that frequentism is an embarrassment, but it is actually an embarrassment of riches."
In my Nobel Prize and Statistical Significance, I show that some current and past Nobel Prize winners and their colleagues use p-values and statistical significance language and concepts in their papers. Therefore, these things are not only used in science, but at the highest levels of science.
Also, check out Google's Quantum Supremacy Using a Programmable Superconducting Processor article, specifically the paper it links to and the supplementary information that paper links to. I show in my Quantum Computing and Statistical Significance that there are plenty of examples of p-values, statistical significance, hypothesis testing, sampling, and bootstrapping (ie. all frequentist notions) in their important contribution.
In Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort, responding to the paper "The illogic of statistical inference for cumulative science" by Guttman (1985), they remark that "Although related to hypothesis testing, confidence distributions are good for cumulative science. To get the most out of an observed set of data, the best possible confidence distribution should be used."
Those wanting to get rid of null hypothesis testing want to go against science. Without a null-hypothesis test, statistical practice would be at odds with scientific reasoning, namely that the burden of proof is on those putting for the more complicated hypothesis.
In 2022, the JASP software updated their Bayesian ANOVA for repeated measures method to be more in line with a frequentist model (see Bayesian Repeated-Measures ANOVA: An Updated Methodology Implemented in JASP).

The change was made because the frequentist model has more reasonable assumptions about the effects and it is what analysts expect/want. But wait, I thought frequentism was supposedly bad for science? I do wonder how many analyses were done that used the previous Bayesian ANOVA method that could now have different results.
- P-values are on the randomness scale, but Bayesian is on the evidence and the clinical scale The critic is confused, because the Bayesian approach might be on the subjective, brittle prior scale, which is not exactly what I would equate with evidence.
- Folly of randomization In Probability Theory: The Logic of Science, by Jaynes, he shows how Monte Carlo approximation of an integral involving an f(x) in a unit square is not as efficient as a uniform grid search. However, the folly here is Jaynes. He does not also consider real-world resources involved with sampling, matters of bias, nor existence of gradients, which make the random points approach superior in its combination of mathematical and practical efficiency. For example, if you're sampling along a road in a city, and there is an empty lot between each house, and your uniform grid samples every other lot, you're going to sample all houses or all empty lots. There are many mathematical and practical examples of the many benefits of randomization.
- Cauchy distribution is problematic for frequentism The critique is that estimating the mean and standard deviation through samples from a Cauchy distribution is problematic because it does not converge with more samples, and therefore frequentism is bad. First, does this admit that convergence for the /many more times there is convergence in these types of problems with non-Cauchy distributions show that frequentism is good? In any case, the Cauchy distribution is a so-called pathological distribution. One can estimate a location parameter using the median instead of mean, use various iterative methods for the maximum likelihood estimate, or truncate. Note, that the Cauchy distribution is a theoretical distribution, and in real life, we never know the true distribution, F. The types of Bayesian priors used for this problem just serve to eliminate the fat tails of the Cauchy distribution.
- Frequentist Funnel Because frequentism is more "Swiss army knife" than "hammer for every job", frequentism is flexible, and can therefore even adopt Bayesian procedures, provided they have good frequentist properties (the output in the "Frequentist Funnel")

- P-values overstate evidence for H0 A few questions: Is this only considering one trial or repeated trials? Is overstating evidence always worse than understating evidence? In any case, the answer to "do p-values overstate evidence for H0?" is, it depends. There are cases where frequentist and Bayesian approaches coincide, and times where one approach overstates or understates. See Reconciling Bayesian and Frequentist Evidence in the One-Sided Testing Problem by Casella and Berger. Note that the definitions of "evidence" are different between frequentist and Bayesian approaches. A Bayesian might like a posterior probability from one experiment, while a frequentist might prefer a p-value from repeated (ideally) experiments.
- Bayesian approaches are used in clinical trials Bayesian and frequentist methods are both used in clinical trials, and probably frequentist methods take the edge for scientific rigor, especially in Phase III trials. Also, read The case for frequentism in clinical trials by Whitehead. He writes
"What of pure Bayesian methods, in which all conclusions are drawn from the posterior distribution, and no loss functions are specified? I believe that such methods have no role to play in the conduct or interpretation of clinical trials."
...
"The argument that in a large trial, the prior will be lost amongst the real data, makes we wonder why one should wish to use it at all."
...
"It disturbs me most that the Bayesian analysis is unaffected by the stopping rule."
...
"I do not believe that the pure Bayesian is allowed to intervene in a clinical trial, and then to treat the posterior distribution so obtained without reference to the stopping rule."Also, see There is still a place for significance testing in clinical trials by Cook et al. They say (bolding mine)
"The carefully designed clinical trial based on a traditional statistical testing framework has served as the benchmark for many decades. It enjoys broad support in both the academic and policy communities. There is no competing paradigm that has to date achieved such broad support. The proposals for abandoning p-values altogether often suggest adopting the exclusive use of Bayesian methods. For these proposals to be convincing, it is essential their presumed superior attributes be demonstrated without sacrificing the clear merits of the traditional framework. Many of us have dabbled with Bayesian approaches and find them to be useful for certain aspects of clinical trial design and analysis, but still tend to default to the conventional approach notwithstanding its limitations. While attractive in principle, the reality of regularly using Bayesian approaches on important clinical trials has been substantially less appealing - hence their lack of widespread uptake."
...
"It is naive to suggest that banning statistical testing and replacing it with greater use of confidence intervals, or Bayesian methods, or whatever, will resolve any of these widespread interpretive problems. Even the more modest proposal of dropping the concept of 'statistical significance' when conducting statistical tests could make things worse. By removing the prespecified significance level, typically 5%, interpretation could become completely arbitrary. It will also not stop data-dredging, selective reporting, or the numerous other ways in which data analytic strategies can result in grossly misleading conclusions." - Trustworthiness of statistical inference In Trustworthiness of statistical inference by Hand, he notes that
We examine the role of trustworthiness and trust in statistical inference, arguing that it is the extent of trustworthiness in inferential statistical tools which enables trust in the conclusions. Certain tools, such as the p‐value and significance test, have recently come under renewed criticism, with some arguing that they damage trust in statistics. We argue the contrary, beginning from the position that the central role of these methods is to form the basis for trusted conclusions in the face of uncertainty in the data, and noting that it is the misuse and misunderstanding of these tools which damages trustworthiness and hence trust.
- success of meta-analysis The general results of standard meta-analysis, for example, by Cochrane and others, demonstrate that compilation of frequentism over time produces scientific knowledge.
- There are many published false positives. Therefore, frequentism is bad Any false positive is a result of working with data, where making a decision entails risk, as well as the fault of arbitrary journal standards, such as requiring "statistical significance" to be p < .05 before they will consider publishing your work. The same thing could easily occur with Bayes factor (BF) cutoffs. Not to mention, Bayesian and other false positive calculators are very sensitive to choice of priors and other assumptions. Also see Why Most Published Research Findings Are False by Ioannidis.
- The false positive rate in single tests of significance show p-values don't work The false positive rate work by Cohen, Colquhoun, and others, are attempts to derive the probability that a statistically significant result was a false positive, and that the false positive is large even for reasonable assumptions. Unfortunately, the assumptions aren't that reasonable. First, they tend to be based on interpreting the p-value found in a single test. However, we know that a single test is only an indication, and doesn't conclude anything. Fisher himself worked on these problems and mentioned this about 80 years ago. Second, a hypothesis is always a statement about the population and not the sample. Third, Colquhoun, for example, is not convincing to me when he wants to count p-values a certain way (equal instead of less than or equal to).
These Bayesian/screening/likelihood interpretations of frequentist significance testing pop up year after year and keep getting swatted back down. They are admittingly somewhat seductive because they seem true and are based on simple arithmetic. Hagen discussed this a little in In Praise of the Null Hypothesis Statistical Test. In one of Hagen's examples, from Cohen, he merely considers one replication using P(H0|sig test) from the previous experiment. After a few replications, the so-called false positive rate argument is completely moot. Are we to believe that a critique of frequentist significance testing based on a single experiment should be taken seriously?
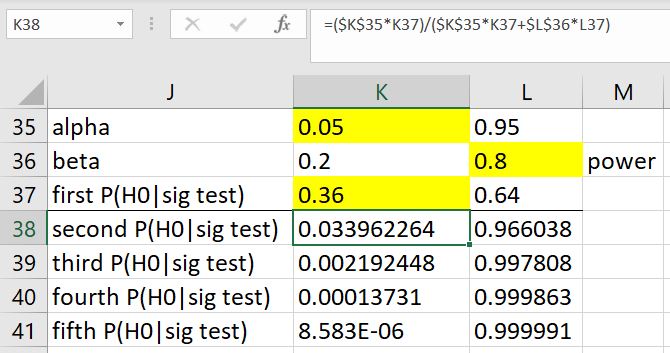
Such criticisms also contradict "the null is always false" charge somewhat.
- There are proofs of God existing, the resurrection of Jesus, and other miracles, that rely on Bayesian statistics These are silly, but use priors correctly, arguably, especially in the subjective Bayesian paradigm. Some argue that it was Bayes'/Price's intention to use the theorem to refute Hume's argument against miracles. For some examples, see The Probability of God: A Simple Calculation That Proves the Ultimate Truth by Unwin, The Existence of God by Swinburne, and Bayesian evaluation for the likelihood of Christ's resurrection. Are these therefore a mark against Bayesian statistics as a whole? Of course not! So why should misuses or misunderstandings of frequentist statistics or hypothesis testing or p-values count against frequentism?
Can proofs of god(s) type of nonsense occur with misuses of frequentism? Yes, however I would argue that it is more difficult to logically defend that practice in frequentism compared to subjective Bayes in which anyone dream up an equally valid subjective prior for a parameter (not to mention, the parameter is what you're trying to estimate in the first place). In the 1700s, Arbuthnot in his Argument from Divine Providence examined birth records in London from 1629 to 1710. If the null hypothesis of equal number of male and female births is true, the probability of the observed outcome of there being so many male births was 1/282. This first documented use of the nonparametric sign test led Arbuthnot to correctly conclude that the true probability of male and female births were not equal, given the assumptions of the model and the limitations in the data. However, he then took a huge leap, unwarranted by hypothesis testing or science, and attributed that finding to the god he believed in. Let's note that this frequentist proof of god(s) was over 300 years ago, but note that the proofs/disproofs of god(s) using Bayesian probability are not only 300 years ago but are also (shamefully) used in modern times.
- Examples of Bayesian probability or statistics not working, or paradoxes There are examples, but they are often not well-known or popularized. There are also examples of generally good science like Bayesian Methods in the Search for MH370 that do not seem to be working.
Note, searches using these and related search theory methods have helped find submarines and other planes (although they are never the only thing used in the search). On this important issue, statistician Mike Chillit has said
"...while Bayesian is a powerful analysis tool in the right hands, it is not without risk. A Bayes formula that is front-loaded with a controlling assumption that MH370 "flew due south with no human input until fuel was exhausted" will always return whimsical results unless that is precisely what happened."
"By far the most serious error in this search was the attempt to make Bayesian statistics resolve location issues. In truth, Bayesian cannot be constructed even after the fact to find the correct location. It is simply not the tool for this challenge."
"They thought they were incredibly clever. Bragged about their analysis skills in endless articles; spent more time writing a book on Bayesian than looking. They believed they'd find it within a month. But the analysis was way beyond naive."
In 11/2021, Zillow exited from the home flipping business. Apparently its algorithm/model to buy and sell homes, that relied on Bayesian methods, did not work as expected. This resulted in reportedly a 25% workforce reduction, 7,000 unsold homes bought for $2.8B (with an expected $304M write-down in Q4), a 30% stock drop, and $245M in losses for Q3. Oopsies! This is not to say frequentist methods could have done any better however.
- Frequentists have to use NHST This is false. A big appeal of frequentism is the flexibility and a choice besides 'pure' NHST is equivalence testing. See Equivalence Testing for Psychological Research: A Tutorial by Lakens et al. Equivalence testing basically consists of determining the smallest effect size of interest (SESOI) and constructing a confidence interval around a parameter estimate. Using both NHST and equivalence tests might help prevent common misunderstandings of p-values larger than α as absence of a true effect, and of the difference between statistical and practical significance. Here is a table showing possible outcomes in equivalence testing
adapted from Lakens possible outcome interpretation reject H0, and fail to reject the null of equivalence there is probably something, of the size you find meaningful reject H0, and reject the null of equivalence there is something, but it is not large enough to be meaningful fail to reject H0, and reject the null of equivalence the effect is smaller than anything you find meaningful fail to reject H0, and fail to reject the null of equivalence undetermined: you don't have enough data to say there is an effect, and you don't have enough data to say there is a lack of a meaningful effect Also, Neyman wrote, a
"region of doubt may be obtained by a further subdivision of the region of acceptance"
indicating that we can do more than just reject and fail to reject quite easily and naturally if we choose to. - Questionable Bayesian research practices Critics of NHST focus on questionable research practices as if they only apply to NHST. However, questionable research practices obviously exist with Bayesian approaches too. Elise Gould has said
"Non-NHST research is just as susceptible to QRPs as NHST."
- Frequentism does not fit in the decision theory framework as easily as a Bayesian approach does The implication is, that therefore you should choose a Bayesian approach. Au contraire. See Why the Decision-Theoretic Perspective Misrepresents Frequentist Inference: 'Nuts and Bolts' vs. Learning from Data by Spanos. Note that this contradicts the "frequentists don't want to deal with hard math" charge somewhat.
Moreover, it is simply false. If there is a family of probability models for the data X, indexed by the parameter θ, there is a procedure d(X) that operates on the data to produce a decision, and we have a loss function l(d(X),θ), the expectations are:
- frequentist expectation: R(θ) = Eθl(d(X),θ)
- Bayesian expectation: p(X) = E[l(d(X),θ)|X]
Before experimentation, one simply doesn't know X or θ.
- German tank problem See Wikipedia's entry on the German tank problem. Frequentism
worked there just fine and Bayes did too, but I would say the frequentist solution is easier to do and
explain. The Wikipedia article says the German tank problem is
"...a practical estimation question whose answer is simple (especially in the frequentist setting) but not obvious (especially in the Bayesian setting)."
- frequentism and law Frequentism and null hypothesis significance testing has proven very effective in law. See Legal Sufficiency of Statistical Evidence by Gelbach and Kobayashi. They say
"Our core result is that mathematical statistics and black-letter law combine to create a simple standard: statistical estimation evidence is legally sufficient when it fits the litigation position of the party relying on it. This means statistical estimation evidence is legally sufficient when the p-value is less than 0.5; equivalently, the preponderance standard is frequentist hypothesis testing with a significance level of just below 0.5."
"Finally, we show that conventional significance levels such as 0.05 require elevated standards of proof tantamount to clear-and-convincing or beyond-a-reasonable-doubt."
- Federalist Papers See Applied Bayesian and Classical Inference: The Case of The Federalist Papers by Mosteller and Wallace. This is a fantastic book where they use frequentist ("classical") discriminant analysis to determine authorship of the Federalist Papers with unknown authorship, and contrast this to using a Bayesian approach. The level of detail they give is mind-boggling, and they really set the standard for these types of analyses. I'd recommend everyone read this book at some point in their statistical life. My take on this work is that the frequentist approach basically gives the same answer (spoiler: Madison) for much less assumptions and work (one can easily see this based on page counts of the frequentist and Bayesian sections). The Bayesian approach here is very dependent on choice of prior distributions and parameters. I'd like to point out that their Bayesian approach also relies heavily on frequencies of words and combinations. Is a Bayesian analysis relying on frequencies a type of frequentism?
- We learn from sampling the world See Sampling Algorithms by Tille. If we have a population of N things and we sample n things, uncertainty about what is being measured decreases as n/N, the "sampling fraction", goes to 1. Another way of looking at this is, if we were to use subjective probability, your belief matters less and less for n increases.
- We learn from repetition We'd have strong suspicion a coin is biased, for example, after flipping it many times and using the Strong Law of Large Numbers (SLLN), as well as using frequentist results from quality control. We'd have a better strategy for game theory situations after more repetitions. See Games and Decisions: Introduction and Critical Survey by Luce and Raiffa.
- Assumptions and Ockham's Razor I believe that frequentism has less assumptions going into it because Bayes has all that frequentism has, plus priors and parameters and hyperparameters, and more overall subjectivity. If we let E stand for an event, and H1 for the one hypothesis, H2 for the other hypothesis, then Ockham's Razor is:
if hypotheses H1(m) and H2(n), with assumptions m and n respectively, explain event E equally well, choose H1 as the best working hypothesis if m < n
- severity The notion of "severity" demonstrates frequentism and hypothesis testing and their relation to good science. See Statistical Inference as Severe Testing: How to Get Beyond the Statistics Wars by Mayo, and Severe Testing as a Basic Concept in a Neyman-Pearson Philosophy of Induction by Mayo and Spanos. It essentially formalizes Popper's notion of thoroughly testing a claim. They write
"The intuition behind requiring severity is that:
Data x0 in test T provide good evidence for inferring H (just) to the extent that H passes severely with x0, i.e., to the extent that H would (very probably) not have survived the test so well were H false."
Also check out What can psychology's statistics reformers learn from the error-statistical perspective? by Haig.
- Nonparametric The nonparametric statistics approach has even less assumptions than standard frequentism or Bayesian statistics. See Nonparametric Statistical Methods by Hollander, Wolfe, and Chicken. Also see Nonparametric Statistical Inference by Gibbons and Chakraborti.
- Tukey's famous quote is perfect for illustrating the need for a Bayesian approach to statistics Tukey's famous quote, is
"An approximate answer to the right question is worth a great deal more than a precise answer to the wrong question."
Critics of frequentism, such as Harrell and Wagenmakers, have tried to use Tukey's quote as an argument for Bayesian approaches. Harrell said "Famous quote by John Tukey provides a great motivation for using the Bayesian approach" with the following image
Of course, sometimes the Bayesian approach doesn't work out that way. Consider this quote from an ESP study: "Bayesian results range from confirmation of the classical analysis to complete refutation, depending on the choice of prior." And in the situation where there was agreement between Bayesian approaches when different priors were used, was there also agreement with a frequentist result? The critic doesn't say.
A frequentist can address the "right question" using various models, testing, confidence intervals, with no need for priors. What the critic terms the "wrong question" is simply using modus tollens logic, which is valid. For example, if we assume a fair coin model and flip a coin 1000 times, the evidence of 997 heads would indicate that the fair coin model is not correct, because we'd expect around 500 heads.
However, Tukey's paper The Future of Data Analysis, in which Tukey's quote appears, mentions "Bayes" just one time despite being 68 pages long, but mentions significance, testing, and non-Bayesian approaches many more times. In this paper, Tukey is talking more about exploratory data analysis (EDA), nonparametric approaches, and robustness issues than any Bayesian approach to statistics.
Additionally, in John W. Tukey's Contributions to Multiple Comparisons, Tukey is quoted as saying the following regarding the Bayesian framework for clinical trials
"I have yet to see a Bayesian account in which there is an explicit recognition that the numbers we are looking at are the most favorable out of k. Until I do, I doubt that I will accept a Bayesian approach to questions of this sort as satisfactory."
In Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort, rephrase Tukey differently, as
"Is it then best to be approximately right, and slightly arbitrary in the result, as in the Fisher-Neyman case, or arriving at exact and unique but perhaps misleading Bayesian results?"
- General skepticism of Bayesian interpretations See Frequentism as Positivism: a three-sided interpretation of probability by Lingamneni.
In it he shows how probability interpretations are hierarchical, as well as says
"...while I consider myself a frequentist, I affirm the value of Bayesian probability...My skepticism is confined to claims such as the following: all probabilities are Bayesian probabilities, all knowledge is Bayesian credence, and all learning is Bayesian conditionalization".
Also see Bayesian Just-So Stories in Psychology and Neuroscience by Bowers and Davis. In it, they say
"According to Bayesian theories in psychology and neuroscience, minds and brains are (near) optimal in solving a wide range of tasks. We challenge this view and argue that more traditional, non-Bayesian approaches are more promising."
Also see Is it Always Rational to Satisfy Savage's Axioms? by Gilboa, Postlewaite, and Schmeidler. In it, they say
"This note argues that, under some circumstances, it is more rational not to behave inaccordance with a Bayesian prior than to do so. The starting point is that in the absence of information, choosing a prior is arbitrary. If the prior is to have meaningful implications, it is more rational to admit that one does not have sufficient information to generate a prior than to pretend that one does. This suggests a view of rationality that requires a compromise between internal coherence and justification, similarly to compromises that appear in moral dilemmas. Finally, it is argued that Savage's axioms are more compelling when applied to a naturally given state space than to an analytically constructed one; in the latter case, it may be more rational to violate the axioms than to be Bayesian."
Also, in an interview Frederick Eberhardt has said
"My thinking is not Bayesian. In fact, years ago, together with David Danks, I wrote a paper arguing that several experiments in cognitive psychology that purported to show evidence of Bayesian reasoning in humans, showed no such thing, or only under very bizarre additional assumptions. It was not a popular paper among Bayesian cognitive scientists."
Also, see Reviving Frequentism, by Hubert. He writes
"Philosophers now seem to agree that frequentism is an untenable strategy to explain the meaning of probabilities. Nevertheless, I want to revive frequentism, and I will do so by grounding probabilities on typicality in the same way as the thermodynamic arrow of time can be grounded on typicality within statistical mechanics. This account, which I will call typicality frequentism, will evade the major criticisms raised against previous forms of frequentism. In this theory, probabilities arise within a physical theory from statistical behavior of almost all initial conditions. The main advantage of typicality frequentism is that it shows which kinds of probabilities (that also have empirical relevance) can be derived from physics. Although one cannot recover all probability talk in this account, this is rather a virtue than a vice, because it shows which types of probabilities can in fact arise from physics and which types need to be explained in different ways, thereby opening the path for a pluralistic account of probabilities."
- Null hypothesis significance testing (NHST) is too difficult with planned/unplanned "data looks" and stopping rules in clinical trials Note that this contradicts the "frequentists don't want to deal with hard math" charge somewhat. On the contrary, various "adaptive designs" have been worked out and more are being explored in medicine, sample surveys, and other areas. See Adaptive Designs for Clinical Trials and the math details by Bhatt and Mehta. Do multiple data looks and etc. make things harder? Absolutely, in frequentist and Bayesian approaches. Are the extra difficulties insurmountable? Probably not. Not to mention, so-called NHST is the dominant statistical method in practice, so how is it too difficult as claimed if most everyone is actually doing it?
- If two persons work on the same data and have different stopping intention, they may get two different p- values. If one stopped after m trials and one stopped after n trials, and m is different than n, obviously the results probably should differ because the data would not be the same as claimed. As mentioned above, things like this could possibly be accounted for in sequential and adaptive design. Frequentism can directly address stopping rule issues, while Bayesian inference sweeps the issue under the rug because it only considers the data that were actually observed (observed data convoluted with a possibly non-observed subjective prior, that is). As Steele notes, Stopping rules matter to Bayesians too. Steele writes
"If a drug company presents some results to us - "a sample of n patients showed that drug X was more effective than drug Y" - and this sample could i) have had size n fixed in advance, or ii) been generated via an optional stopping test that was 'stacked' in favour of accepting drug X as more effective - do we care which of these was the case? Do we think it is relevant to ask the drug company what sort of test they performed when making our final assessment of the hypotheses? If the answer to this question is 'yes', then the Bayesian approach seems to be wrong-headed or at least deficient in some way."
See also Why optional stopping is a problem for Bayesians by Heide and Grunwald.
Fisher dislike or envy
- I dislike Ronald Fisher, therefore frequentism is false Most of the dislike is Fisher envy. He created maximum likelihood, experimental design, ANOVA, F distribution, sufficiency, co-founder of the field of population genetics, conducted important research on natural selection and inheritance, fiducial probability/confidence distribution idea, and gave us many statistical terms. What have any critics of frequentism, or any prominent Bayesians for that matter, done in comparison? A case of sour grapes perhaps? Some quotes I found on Fisher are:
- greatest statistician ever
- one of the greatest scientists in the 20th century
- greatest biologist since Charles Darwin
- "a genius who almost single-handedly created the foundations for modern statistical science"
- "To biologists, he was an architect of the "modern synthesis" that used mathematical models to integrate Mendelian genetics with Darwin's selection theories. To psychologists, Fisher was the inventor of various statistical tests that are still supposed to be used whenever possible in psychology journals. To farmers, Fisher was the founder of experimental agricultural research, saving millions from starvation through rational crop breeding programs"
- Statistical Methods for Research Workers occupies a position in quantitative biology similar to Isaac Newton's Principia in physics
- "Many people contributed to the construction of distributions to represent directional data. No real progress was made with the inference questions until the problem was drawn to the attention of the late Sir Ronald Fisher (1953) by geophysicists interested in palaeomagnetism."
- Fisher liked smoking, therefore frequentism is false The likes of a man or woman have no bearing on statistical theory. Obvious? He did accept the correlation between smoking and lung cancer, but not the causation. He said more research needed to be done on the issue.
To illustrate another way, Harold Jeffreys was a strong opponent of continental drift, therefore Bayesian probability and statistics are false. Nope, this is a very poor argument. Also, Jeffreys was a smoker.
Interestingly enough, Fisher was involved with highly original mathematics for a test of significance and confidence interval (circle/cone) for observations on a sphere in his Dispersion on a Sphere. Fisher solved the statistics questions posed by Runcorn, whose ideas moved us away from "the static, elastic Earth of Jeffreys to a dynamic, convecting planet", as detailed in From polar wander to dynamic planet a tribute to Keith Runcorn. Another interesting fact is that von Mises also worked on distributions in non-Euclidean spaces.
- Fisher studied eugenics, therefore frequentism is false Studying eugenics was socially acceptable at the time. Clayton in his Bernoulli's Fallacy: Statistical Illogic and the Crisis of Modern Science discusses eugenics beliefs of Fisher and others, and attempts to link frequentism to Nazis. In The Outstanding Scientist, R.A. Fisher: His Views on Eugenics and Race by Bodmer, Senn, et al we find this quote from Fisher (the full quote that Clayton does not present)
"As he has been attacked for sympathy towards the Nazi movement, I may say that his reputation stood exceedingly high among human geneticists before we had heard of Adolph [sic] Hitler. It was, I think, his misfortune rather than his fault that racial theory was a part of the Nazi ideology, and that it was therefore of some propaganda importance to the Nazi movement to show that the Party supported work of unquestioned value such as that which von Verschuer was doing. In spite of their prejudices I have no doubt also that the Party sincerely wished to benefit the German racial stock, especially by the elimination of manifest defectives, such as those deficient mentally, and I do not doubt that von Verschuer gave, as I should have done, his support to such a movement. In other respects, however, I imagine his influence was consistently on the side of scientific sanity in the drafting and administration of laws intended to this end."
The article by Bodmer, Senn, et al goes on to say:
These statements have been interpreted by some as suggesting that Fisher referred to elimination in the sense of killing or at least compulsory sterilisation or institutionalisation, and so was a Nazi sympathiser. This is, however, in obvious disagreement with his very clearly stated views that sterilisation should be voluntary and consistent with his support for the Brock report.
In other words, Fisher was a genetics sympathizer, not a Nazi sympathizer.
Asher in her JSM 2021 "R.A. Fisher and Eugenics: A Historical Overview" presentation, discusses examples of Fisher's racism and examples of non-racism, and distinguishes between positive and negative eugenics, noted eugenists advocated some good and some bad. It seems Fisher believed in differences between some groups based on what he perceived as evidence, but respected individuals from different races. A comment made by someone watching the presentation was "people are not stock animals". But doesn't that go against scientific knowledge that people are essentially animals? There was also the typical comment of something like 'Nazi's liked eugenics', which confuses P(eugenic interest|Nazi) with P(Nazi|eugenic interest).
Fisher doing experimental agricultural research to save millions from starvation through rational crop breeding programs? Neyman was a human rights activist? Don't mention those things about frequentists.
- If Fisher (Neyman, Pearson, etc.) were alive today, they'd be Bayesians too! Wait, I thought critics of frequentism weren't supposed to engage in counterfactuals? In any case, one could easily opine that today's modern computing environment would lead them more away from Bayesian approaches and into permutation, bootstrap, and nonparametric approaches.
- I do not like the label "Inverse Probability" for Bayesianism, therefore frequentism is false Some critics, who are unaware of the history of probability and statistics, claimed that Fisher created the term "Inverse Probability" and that this was intellectually dishonest. In contrast, "direct probability" refers to the likelihood, because that is where the data you directly observe enter, whereas "inverse probability" refers to probability distributions of unobserved parameters. However, the term "inverse probability" for Bayesian probability was used long before Fisher in an 1830's paper by de Morgan, who was referencing work by Laplace. In fact, early on Fisher used the term "inverse probability", but later was one of the first to use the adjective "Bayesian". Fienberg discusses this in When Did Bayesian Inference Become "Bayesian"?.
Fisher said a large p-value means "get more data" and nothing more. I read this quote a lot from a critic of frequentism. Although, when I search for "Fisher" and "get more data", all I find are posts from that critic and not exact quotes from Fisher. Let's look at what Fisher himself actually wrote. In Statistical Methods for Research Workers, Fisher wrote (supposing α=.05) "If P is between .1 and .9 there is certainly no reason to suspect the hypothesis tested"
...
"...P is between .8 and .9, showing a close...agreement with expectation"- Fiducial probability was a failure! Was it, or was/is it misunderstood? Actually, it seems that fiducial probability was a success for simple cases but possibly not well-defined in more general settings. Confidence distributions (CD) are distribution functions that can represent confidence intervals of all levels for parameters of interest. CDs are extremely fruitful, enabling us to solve all sorts of statistical problems in prediction, testing, simulation and meta analysis, and quite possibly even providing a unifying framework for Bayesian, likelihood, fiducial, and frequentist schools. Far from being a failure, Fisher (again) seems to have paved the way with his work on fiducial probability. See Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort.
Efron (Statistical Science, 1998) has said
"... here is a safe prediction for the 21st century: ...I believe there is a good chance that...something like fiducial inference will play an important role... Maybe Fisher's biggest blunder will become a big hit in the 21st century!"
The computations for CDs can also contradict the "frequentists don't want to deal with hard math" charge, since Schweder and Hjort in Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions said "...they might be more computationally demanding than the Bayesian posterior."
Fraser (2011) has also said that Bayesian posterior distributions are just quick and dirty confidence distributions.
There is the Bayesian, Fiducial, and Frequentist = Best Friends Forever (BFF) community that begain in 2014, as a means to bridge foundations for statistical inference. Fiducial inference seems to be a way to connect everything.
- Fisher championed randomizing because it gives a distribution to the error term (among other benefits). Fisher also thought of inference using statistics as a way for regular people to make sound decisions without having to rely on "experts" dominating the conversation. Perhaps such "experts" dominate the conversation through use of priors. These concepts were ahead of their time.
- Fisher noted that Bayes's famous example relied on an experiment for the prior probabilities (Fisher recommended updating the billiard table with a source of radioactive decay), as well as that Bayes rejected the idea of introducing them axiomatically.
- But...Fisher! Complain about Fisher all you'd like, but many others have also pointed out various flaws in the Bayesian approach, for example Boole, Venn, von Mises, Kempthorne, Lecam, Neyman, Mayo, Efron, Wasserman, Pearl, Taleb, and on and on. Critics need to address the flaws rather than the person.
- Fiducial probability was a failure! Was it, or was/is it misunderstood? Actually, it seems that fiducial probability was a success for simple cases but possibly not well-defined in more general settings. Confidence distributions (CD) are distribution functions that can represent confidence intervals of all levels for parameters of interest. CDs are extremely fruitful, enabling us to solve all sorts of statistical problems in prediction, testing, simulation and meta analysis, and quite possibly even providing a unifying framework for Bayesian, likelihood, fiducial, and frequentist schools. Far from being a failure, Fisher (again) seems to have paved the way with his work on fiducial probability. See Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort.
Frequentism is used to p-hack.
- Frequentism is used to p-hack The loudest claims of "p-hacking" may really just be "p-envy", or perhaps what Wasserman calls "frequentist pursuit". If anything, Bayesian inferences can increase these problems, or create a different set of problems, because in addition to the usual myriad of things
to choose from in any analysis, now we have an infinite number of priors and other statistics we can choose from. See Degrees of Freedom in Planning, Running, Analyzing, and Reporting Psychological Studies: A Checklist to Avoid p-Hacking by Wicherts, Veldkamp, et al, for a good discussion of p-hacking. Also, make sure not to look at data prior to making the prior, and don't retry your analysis with different priors. Of course, any method, frequentist or Bayesian (or anything else), can be "hacked" or "gamed". The article Possible Solution to Publication Bias Through Bayesian Statistics, Including Proper Null Hypothesis Testing by Konijn et al discusses "BF-hacking" in Bayesian analysis, and notes
"God would love a Bayes Factor of 3.01 nearly as much as a BF of 2.99."
- Pre-registration The idea for all scientific studies to "pre register" to help prevent scientist/researcher p-hacking/prior-fiddling behavior I think is really great, for Bayesian, frequentist, anything.
- Frequentism is "ad hoc" Is "ad hoc" a bad word? There are many ways to interpret
even simple 2x2 tables, but why is that bad? Trying to sell "ad hoc" as being something bad and "magical thinking" is not sensible. In fact, "ad hoc" just means "as needed" or "done for a particular purpose", which is quite sensible. Frequentist methods are free and not tied down to any single approach. Therefore, frequentist methods don't suffer from "every problem requires the same tool" (ie. Bayes rule), which can be extremely limiting. For example, consider constructing a confidence interval for a proportion. Some of the methods to do this are: Clopper-Pearson, Wilson, Wald, Agresti-Coull, arcsine, logit, Witting, Pratt, mid-p, likelihood-based, Blaker, and others. In addition, there are a variety of bootstrap methods for a confidence interval of a proportion.
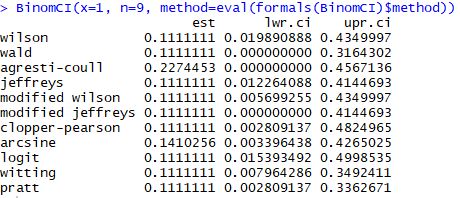
Note, this contradicts the "frequentists apply their stuff too mechanistically" charge.
Let's talk about priors. How many ways can we assign priors, hyperparameters, etc.? How often do Bayesians go back and tweak their prior to get convergence or the prior predictive distribution or other results "just right"?
- Specifying statistical tests is too arbitrary Mostly one conditions on sufficient statistics. Is specifying a prior not arbitrary? Where do you stop with parameters on priors, hyperparameters, and on and on. Conjugate priors seem completely artificial (conjugacy is a term for the combination of the prior with the likelihood that yields a posterior belonging to the same family of distributions as the prior, which simplifies the analyses).
- Frequentists apply their methods too mechanistically Bayesians too. Get prior. Get likelihood. MCMC to get posterior. Use posteriort for priort+1 ("today's posterior is tomorrow's prior"). Both, however, are caricatures. The careful statistician, Bayesian or frequentist, does not operate mindlessly. Of course, this contradicts the "ad hoc" charge somewhat.
Frequentism is responsible for the "replication crisis".
- Cutoff of p<.05 is arbitrary Fisher noted this years ago. He said
"It is open to the experimenter to be more or less exacting in respect of the smallness of the probability he would require before he would be willing to admit that his observations have demonstrated a positive result. It is obvious that an experiment would be useless of which no possible result would satisfy him".
See his Statistical Methods, Experimental Design, and Scientific Inference Arbitrary cutoffs are a standard of many journals, not any problem with the statistical theory itself. What is causing you to publish there? What is causing you from just reporting the observed p-value? What is causing you to not use a different α? Why are you not also focusing on experimental design and power? Why don't you replicate your experiment yourself a few times before thinking about publishing? The Neyman-Pearson approach looks more at rules to govern behavior and helping to insure that in the long run we are not often wrong.However, "arbitrary" does not mean there is no reasoning at all behind using α = .05. Fisher basically said it was convenient, and resulted in a z-score of about 2, and made tables in his books (pre-computer times) easier. More importantly, the use, as Fisher knew and wrote about, roughly corresponded to previous scientific conventions of using probable error (PE) instead of standard deviation (SD). The PE is the deviation from both sides of the central tendency (say a mean) such that 50% of the observations are in that range. Galton wrote about Q, the semi-interquartile range, defined as (Q3-Q1)/2, which is PE, where Q3 is the 75th percentile and Q1 is the 25th percentile. For a normal distribution, PE ~ (2/3)*SD. Written another way, 3PE ~ 2SD (or a z-score of 2). The notion of observations being 3PE away from the mean as very improbable and hence "statistically significant" was essentially used by De Moivre, Quetelet, Galton, Karl Pearson, Gosset, Fisher, and others, and represents experience from statisticians and scientists. See On the Origins of the .05 Level of Statistical Significance by Cowles and Davis.
Setting α does not have to be totally arbitrary, however. α is the probability of making a Type 1 error, and should be set based on the cost of making a Type 1 error for your study, as well as perhaps based on the sample size in your study. For example, in "The Significance of Statistical Significance", Hal Switkay suggests roughly setting α based on 1/sample size. Any cutoff, such as cutoffs for determining "significant" Bayes factors, if not set with some reasoning, can also run into the same charge of being arbitrary.
Moreover, there is ample evidence to show that using α=.05 has lead to good science. For example, see When the Alpha is the Omega: P-Values, 'Substantial Evidence,' and the 0.05 Standard at FDA, by Kennedy-Shaffer.
- big data Mayo writes "In some cases it's thought Big Data foisted statistics on fields unfamiliar with its dangers.."
- Wrong definition of "replication crisis" The standard meaning of "replication crisis" is that the effect size, or statistic, or general results of a current study did not match or reproduce those of a previous similarly designed study. However, that is not the standard experimental design definition of a "replication". The only thing "replication" means in experimental design is that the similarly designed study was conducted, and not that it obtained a similar effect size or statistic as a previous similarly designed study. In other words, if the replication "goes the other way", that is actually good information for scientific knowledge, and not a "crisis" which is the standard narrative being perpetuated.
- The "replication crisis" was/is caused by frequentist null hypothesis significance
testing Everyone knows that a replication is technically never absolutely identical to another
replication. In real life, we come as close as we can in the experimental setup, and this is the
"similar" category. Plus, we are working with random data. No matter if frequentist or Bayesian, our
decisions will have errors associated with them because of this fact of nature.
One could argue as Mayo does that the "attutide fostered by the Bayesian likelihood principle is largely responsible for irreplication". That is, it tends to foster the ideas that we don't have to worry about selection effects and multiple testing if we use Bayesian methods.
- Frequentism only considers sampling error This is a very common misconception held by critics of frequentism. The total survey error approach in survey statistics, for example, focuses on many types of errors, not just sampling error. In the 1940s, Deming discussed many types of non-sampling errors in his classic Some Theory of Sampling. Also see Total Survey Error in Practice by Biemer, Leeuw, et al. It is also very necessary to mention Pierre Gy's theory of sampling. Gy developed a total error approach for sampling solids, liquids, and gases, which is very different from survey sampling. See A Primer for Sampling Solids, Liquids, and Gases: Based on the Seven Sampling Errors of Pierre Gy by Patricia Smith. Statisticians do their best to minimize sampling and non-sampling errors.
- With a large enough sample size you can declare anything statistically significant Merely increasing sample size, while increasing power, increases the tests sensitivity, and this shows up in severity measure. Additionally, increasing n by say b data points will only really matter if you get the "right data" to make your measure statistically significant after adding the b additional pieces of data.
- You can't learn anything from hypothesis testing, or all you learn is that it is unlikely you would have gotten these data if the null were true and there is literally no alternative theory to estimate the probability of, just "not null." Bayesian and other critics often attempt to limit frequentism to be only null hypothesis significance testing, which in reality is just a single component of what is under the umbrella of frequentism. We understand that knowledge does not happen in a vacuum, and the combination of experimental design, science, survey sampling, and other sound statistics, and "all you learn" from hypothesis testing can be quite a lot. See the deflection of light example from above. Additionally, the Neyman-Pearson tests can be the most powerful or uniformly most powerful, which seems very important. Wikipedia notes that Neyman-Pearson tests are used in things like economics of land value, electronics engineering, design and use of radar systems, digital communication systems, signal processing systems, minimizing false alarms or missed detections, particle physics, and tests for signatures of new physics against nominal Standard Model predictions.
- But p-values dance around! See Cumming's Dance of P-Values and a similar dance video by Dragicevic. Also check out Lakens' Dance of the Bayes Factors

The main takeaway is: data changes and therefore any functions of it will change. Shocking, I know. What is next, articles from statisticians revealing that water is wet? Tell me again how this is supposedly evidence that p-values don't work? I don't see the connection whatsoever.
- P-values can tell us something about replication probability P-values can tell us something about replication probability while avoiding issues with a Bayesian approach. See the Wiki entry on P-rep and Killeen's original paper.
- All null models are actually false, therefore hypothesis testing is worthless This is somewhat irrelevant as "all models are false, some are useful"
- Null results from hypothesis testing aren't useful
- This is totally false. See HEP physics looking at p-values.
In it they say
"Statistical methods continue to play a crucial role in HEP analyses; recent Higgs discovery is an important example. HEP has focused on frequentist tests for both p- values and limits; many tools developed."
- Another example is economic activity in a NAICS, looking at changes from year to year (null is no change). This information is used by agencies in their official statistics for gross domestic product (GDP), income accounts, and policy decision making.
- Another example is in medicine. See Effects of n-3 Fatty Acid Supplements in Diabetes Mellitus, where a null result was very useful.
- I believe changepoint analysis is a (yet another) great example of the importance and success of hypothesis testing. Changepoint detection is the task of estimating the point at which various statistical properties of a sequence of observations change. In the paper changepoint: An R Package for Changepoint Analysis by Killick and Eckley write
"The detection of a single changepoint can be posed as a hypothesis test. The null hypothesis, H0, corresponds to no changepoint (m = 0) and the alternative hypothesis, H1, is a single changepoint (m = 1)"
- determining terms in regression models
- scientific evidence for claims that there is no association between things, like between autism and vaccinations or fluoride.
- This is totally false. See HEP physics looking at p-values.
In it they say
- Frequentism focuses on proper variance estimation The "right" variance is key in survey design (and all areas) because it allows you, for example, to get an accurate denominator in a test statistic (observed-expected)/standard error, and hence a more correct probability and decision. See Introduction to Variance Estimation by Wolter.
- Frequentists suffer from dichotomania- always making a decision based on two forced outcomes, such as reject or fail to reject As mentioned, frequentism is not just null hypothesis significance testing. But, if we focus on that and need to make a decision, logically our choices need to exhaust the parameter space. If one wants to make a Yes/No decision, frequentism would provide estimates and just about any other statistic, not just the Yes/No decision. Of course, other times we may have more than two decisions to decide from, and frequentism handles these cases as well. I personally would rather "suffer from dichotomania" and make decisions than suffer from extreme subjectivity, using brittle priors, and pretending belief is probability. Of course, not making a decision is also making a decision, so the criticism is somewhat moot.
- P-values are bad, but my other statistic is better See In defense of P
values by Murtaugh. The p-value, CI, AIC, BIC, BF, are all very much related. I think about a p-value as a test statistic put on a different scale. Saying a p-value is "bad" is like saying use Fahrenheit (F) over Celsius (C) because C is bad. As an example, consider that the world starts using Bayes Factors (BF) instead of p-values. A question naturally arises, for what values of BF do things become something like "statistically significant"? Consider the following informal loose correspondence between p-values and BF:
p-valueCorresponding Bayes Factor.053 - 5.0112 - 20.00525 - 50.001100 - 200
Perhaps there would be academic journals that would not let one publish if the BF is not greater than 5. Maybe there would be replications of studies that had large BF that now have a smaller BF. There would probably be plenty of papers saying we need reform because of the misunderstanding of BF even among professional statisticians, or that some other statistic or approach is better than BF. A few people would mention that the first users of BF pointed out these stumbling blocks on misuses of BF a long time ago. One sees the point I hope. Statisticians also use tables, graphs, and other statistics to make conclusions, so an over-emphasis on p-values, BF, etc., is somewhat misguided.
Also see Thou Shalt Not Bear False Witness Against Null Hypothesis Significance Testing by García-Peréz. Among other points, he notes the finding that a Bayes factor is essentially only a transformation of the p-value.
- Bayes Factors get it right! Jahn, Dunne, and Nelson (1987) report that in 104,490,000 trials 52,263,471 ones and 52,226,529 zeros were observed in an ESP experiment where a subject claimed to be able to affect a stream of ones and zeros. The frequentist p-value was less than .01, and therefore H0 was rejected. However, the Bayes Factor was 12, and therefore H0 was not rejected. Some critics of frequentism therefore conclude that frequentists would have claimed this is evidence for ESP, while Bayesians would have claimed this does not provide evidence for ESP, implying therefore Bayes Factors are correct and p-values are flawed. There are several reasons why this is a silly example
- because ESP claims go against how we understand the world works, frequentists would not use that large of an α
- because the n is extremely large, frequentists would not use that large of an α
- frequentists would interpret results from 1 experiment as an indication rather than evidence
- frequentists would require the experiment to be replicated one or two more times
- frequentists would require the experiment to be replicated one or two more times by independent parties
- I very much question Jahn, Dunne, Nelson, Dobyns, PEAR, etc., design, analysis, and implications, for example in my Decision Augmentation Theory: A Critique
- skeptical thinkers and clubs (JREF and others) are highly skeptical of their results
- their results were not published in a mainstream science journal
- critics of p-values did NOT read the ESP paper but cherrypicked! In the paper, the authors state "Whereas a classical analysis returns results that depend only on the experimental design, Bayesian results range from confirmation of the classical analysis to complete refutation, depending on the choice of prior."
Just look at all those counterexamples to frequentism!
- Reference class problem A reference class problem (which is not really a problem) exists with not just frequentism, but also Bayesian and all other interpretations of probability. For example, does the prior you're using on the ability of soccer players apply for all players, all male players, all players within a given year, all players on a given team, etc. No matter the measure, we always need to define what it is a measure of. Fisher himself pointed this out in the 1930s and Venn 70 years before that (and Fisher notes that about Venn)! Just like all probabilities are conditional, we all belong to different classes and frequency(male) is different from frequency(male wears glasses), etc. This is why the context of the problem is important where you define all of these things. Often if a class is too small or empty, and could not meet distributional assumptions, one can "collapse" to the next class that is not too small or empty. As an example, consider the North American Industry Classification System, or NAICS, levels. For example, if there were few or no observations in NAICS
11116 "Rice Farming" you could collapse to NAICS 1111 "Oilseed and Grain Farming". If there were few or no
observations in NAICS 1111, you could collapse to NAICS 111 "Crop Production". And last, if there
were few or no observations in NAICS 111, you could collapse to NAICS 11 "Agriculture, Forestry, fishing
and Hunting". A scenario like this could come into play if setting up cells for imputation, for example.
- Frequentism violates the Strong Likelihood Principle Yes in some sense, and so? The likelihood itself doesn't obey probability rules, needs to be calibrated, doesn't have as high of status as probability, and is merely comparative (ie. H0 relative to H1) rather than corroborating (ie. evidence for an H), so using the likelihood alone is not a reasonable way to do science. See In All Likelihood: Statistical Modelling and Inference Using Likelihood by Pawitan. Additionally, the SLP violation charge has also been severely critiqued and found wanting. If the Weak Conditionality Principle is WCP, and the Sufficiency Principle is SP, in On the Birnbaum Argument for the Strong Likelihood Principle by Mayo, she writes
"Although his [Birnbaum] argument purports that [(WCP and SP) entails SLP], we show how data may violate the SLP while holding both the WCP and SP."
Also see Flat Priors in Flatland: Stone's Paradox by Wasserman discussing Stone's Paradox. Wasserman says
Another consequence of Stone's example is that, in my opinion, it shows that the Likelihood Principle is bogus. According to the likelihood principle, the observed likelihood function contains all the useful information in the data. In this example, the likelihood does not distinguish the four possible parameter values. But the direction of the string from the current position - which does not affect the likelihood - clearly has lots of information.
In short, the likelihood principle says that if the data are the same in both cases, the inferences drawn about the value of a parameter should also be the same. The Bayesians and likelihood approaches may view the likelihood principle as a law, but frequentists understand it is not one. Consider some specfic examples of having the same data where the inferences are completely different, as they should be:
Suppose a researcher flips a coin ten times and assumes a null hypothesis that the coin is fair. The test statistic is number of heads. Suppose the researcher observes alternating heads and tails with every flip (HTHTHTHTHT). This yields a very large p-value. Now suppose the test statistic for this experiment was the number of times when H followed T or T followed H. This yields a very small p-value.
Consider "Suppose a number of scientists are assessing the probability of a certain outcome (which we shall call 'success') in experimental trials. Conventional wisdom suggests that if there is no bias towards success or failure then the success probability would be one half. Adam, a scientist, conducted 12 trials and obtains 3 successes and 9 failures. Then he left the lab. Bill, a colleague in the same lab, continued Adam's work and published Adam's results, along with a significance test. He tested the null hypothesis that p, the success probability, is equal to a half, versus p < 0.5. The probability of the observed result that out of 12 trials 3 or something fewer (i.e. more extreme) were successes, if H0 is true, is 7.3%. Thus the null hypothesis is not rejected at the 5% significance level. Charlotte, another scientist, reads Bill's paper and writes a letter, saying that it is possible that Adam kept trying until he obtained 3 successes, in which case the probability of needing to conduct 12 or more experiments is 3.27%. Now the result is statistically significant at the 5% level. Note that there is no contradiction among these two results; both computations are correct."
These examples are not paradoxes, but demonstrate that the experimental design, sampling distribution, and test statistic (ie. taking all evidence into consideration) are of utmost importance in making sound inference. The confidence distributions in these examples (and p-values) would be different. See Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort, showing an example of this.
Additionally, the likelihood principle is violated in Bayesian posterior predictive checking.
- The data that give a two-tailed p-value of .05 is exactly the same data that give a one-tailed p-value of .025 First, there has been a "selection effect" here. Second, it shows that a 2*SE difference is not necessarily weak (of course we would want to repeat the experiment).
- If you flip a coin twice and get two tails, you mistakenly assume p(heads)=0 from the frequentist maximum likelihood estimate. Bayes gets it more right than that. The Bayesian critic assumes he knows the true probability of heads in this situation to even be bothered about not seeing heads in 2 trials in the first place. In any case, one can use a pseudocount method or other methods to handle these small n situations. However, one cannot say much from 2 trials using any method. One could just say in response to this criticism that if you flip a coin a lot of times, the Bayesian mistakengly assumes their prior is important, when it will simply get dominated by the likelihood.
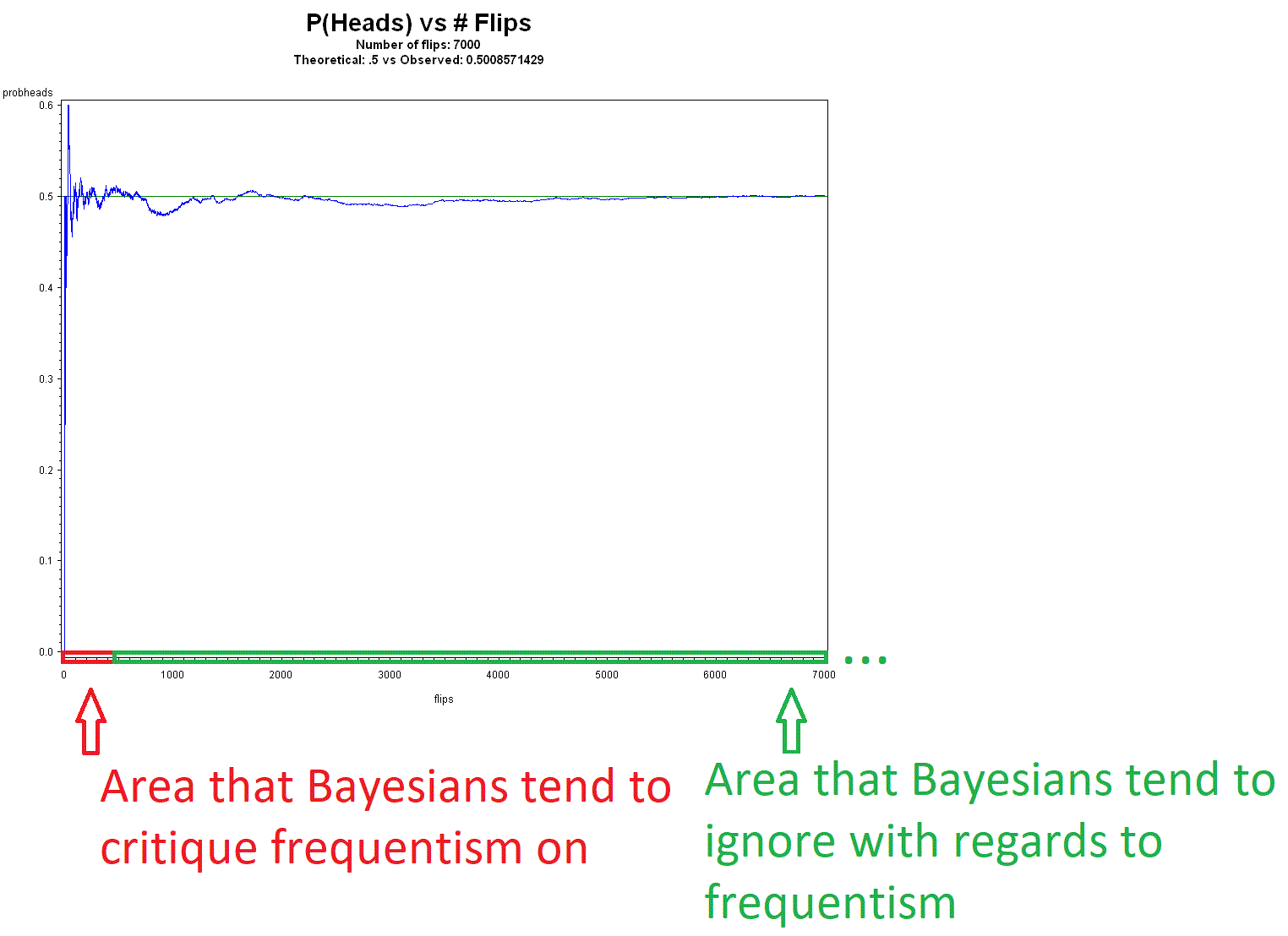
- Assume a male took a test for ovarian cancer with specificity of 99.99%. For H0: no cancer present vs. H1: cancer present, the p-value would be .0001. A frequentist would conclude the male has ovarian cancer. Actually, we don't need statistics for this question. One would find out during an "audit" that the person was male, as well as any other questionable research practices. Why this counterexample prevents the frequentist from knowing the person was male, but presumably allows Bayesians to know that information, is beyond me.
- Comparing A to B should have no influence on comparing C to D. Because it can have an influence, frequentism doesn't make any sense. This gets at pairwise tests based on joint rankings vs. pairwise tests based on separate rankings. In Nonparametrics: Statistical Methods Based on Ranks, Lehmann mentions that a joint ranking uses of all the information in an experiment, namely the spacings between all points, which is lost in a separate ranking procedure. For some data, the separate ranking procedures can perform poorly.
- Maximum likelihood methods, mostly used by frequentists, can have problems when the arbitrarily defined space of possible parameter values includes regions that make no sense. On one hand, this can allow possible parameter values that make little sense (so-called "pathological confidence intervals"). On the other hand, by letting the data speak, it can help prevent subjective beliefs and strong, possibly unwarranted, assumptions from dictating allowable parameter values. Efron has mentioned that one can solve many of these issues by using the bootstrap. One could also use a penalized likelihood approach. Frequentists are not "stuck" using only maximum likelihood.
- Basu's elephant shows the flaws with Horvitz-Thompson (HT) estimators On the contrary, Basu's elephant shows a silly example where you don't do proper survey design. The "paradox" disappears entirely if you create your survey and weights appropriately. For example, weighting by a measure of size (elephant weight). Even in the flawed example, if we had larger n the paradox would disappear. But of course, if the person just wanted to estimate the weight of all elephants by using the weight of a single elephant, then just state your assumptions and methodology and just do it, and there is no need for HT or any other type of sampling whatsoever.
- Various confidence interval (CI) paradoxes There are some well-known paradoxes with confidence intervals.
- Is the confidence 100% or 50%, or 75%? From In All Likelihood: Statistical Modelling and Inference Using Likelihood by Pawitan (adapted from Berger and Wolpert)
Someone picks a fixed integer θ and asks you to guess it based on some data as follows. He is going to toss a coin twice (you do not see the outcomes), and from each toss he will report θ+1 if it turns out heads, or θ-1 otherwise. Hence the data x1 and x2 are an i.i.d. sample from a distribution that has probability .5 on θ-1 or θ+1. For example, he may report x1 = 5 and x2 = 5.
The following guess will have a 75% probability of being correct:
C(x1, x2) =
x1-1, if x1 = x2
(x1+x2)/2, otherwiseHowever, if x1 ne x2, we should be 100% confident that the guess is correct, otherwise we are only 50% confident. It will be absurd to insist that on observing x1 ne x2 you only have 75% confidence in (x1+x2)/2.
First, you have to love us mathematical statisticians because this example is one of the most contrived examples I've ever seen! Second, there is actually no paradox because the "confidence" is in the entire process. If you want to break down a process into subsets of the process (the 100% or 50% parts), you can do that as well. This "paradox" is basically the confidence interval version of the reference class problem. See this spreadsheet for a simulation.
- Jaynes' truncated exponential failure times example Consider the model
p(x|θ) =
e(θ-x), if x > θ
0, if x < θWe observe {10, 12, 15}. What is a 95% confidence or credible interval for theta if it is known that θ must be less than 10? It turns out that a naive frequentist confidence interval, using an unbiased estimator approach, gives a 95% confidence interval of (10.2, 12.2). The fact that the lower limit of the confidence interval is greater than 10 is a problem because logically θ must be smaller than the smallest observed data. The Bayesian credible interval, using a flat prior, gives a 95% credible interval of (9, 10) which is more realistic. This example unfortunately doesn't permit the frequentists to consider any other approach for calculating confidence intervals. I believe order statistics (for example the minimum) and bootstrap (as well as confidence distributions) could be useful with this problem. See this spreadsheet for some explorations.
Note that these paradoxes are typically resolved by some of these approaches
- realizing they aren't paradoxes at all ("not a bug but a feature")
- using larger samples
- using different data
- taking information withheld from the frequentist into account
- using other frequentist approaches that the counterexample prohibits
- Is the confidence 100% or 50%, or 75%? From In All Likelihood: Statistical Modelling and Inference Using Likelihood by Pawitan (adapted from Berger and Wolpert)
- Situations where there are a priori constraints that parameters cannot be negative, etc., are problematic for frequentists Situations like observations are from N(μ,sigma2) and μ>=μ0 (thus no confidence interval can start to the left of μ0), or parameters have to be nonnegative are actually not problematic because frequentists are not confined to using one method. See Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort, showing plenty of examples of inference being done taking constraints into account.
- Frequentist testing scenarios that are problematic Perhaps one can find tests and a data set where the following occurs:
- First test equality of variances assuming possibly different means. Find they are equal variance.
- Test equality of means assuming equal variance. Find the means are different.
- First test equality of means assuming possibly different variances. Find they are equal means.
- Test for equality of variance assuming a common mean. Find the variances are different.
- False positives These are not counterexamples but an outcome of working with data and making decisions in the face of risks, and having to conform to arbitrary journal standards. Let's not pretend that there aren't or wouldn't be any false positives if we use a Bayesian analysis.
Counterexamples, paradoxes, or issues in Bayesian probability and statistics
- Consider a prior on the parameter θ where θ ~ U(0,1). What about the distribution of θ2, log[θ/(1-θ)], or 1/θ? It is true that I'd expect θ500 to be closer to 0 than 1, but the general question still stands of how does ignorance on one scale translate into knowledge on another?
- Cromwell's rule. Cannot update priors of 0 away from 0, no matter how much data you obtain. This can be interpreted to mean that hard convictions are insensitive, or even immune, to counter-evidence. Because of this fact, Bayesians are likely to say that all probabilities must really be greater than 0, so Bayesian updating works. Frequentism on the other hand can allow for probabilities of 0 and the relative frequency updating itself away from 0 would still work. For example:
TrialObservationRelative Frequency100/1200/2300/3400/4511/5601/6.........
- Talking about probability using Bayes instead of frequentism is like talking about temperature by seeing how many different layers of clothing people are wearing instead of just looking at properly calibrated thermometers.
- "Bayesian divergence". From Wikipedia
"An example of Bayesian divergence of opinion is based on Appendix A of Sharon Bertsch McGrayne's 2011 book The Theory That Would Not Die: How Bayes' Rule Cracked the Enigma Code, Hunted Down Russian Submarines, and Emerged Triumphant from Two Centuries of Controversy. Tim and Susan disagree as to whether a stranger who has two fair coins and one unfair coin (one with heads on both sides) has tossed one of the two fair coins or the unfair one; the stranger has tossed one of his coins three times and it has come up heads each time.
Tim assumes that the stranger picked the coin randomly - i.e., assumes a prior probability distribution in which each coin had a 1/3 chance of being the one picked. Applying Bayesian inference, Tim then calculates an 80% probability that the result of three consecutive heads was achieved by using the unfair coin, because each of the fair coins had a 1/8 chance of giving three straight heads, while the unfair coin had an 8/8 chance; out of 24 equally likely possibilities for what could happen, 8 out of the 10 that agree with the observations came from the unfair coin. If more flips are conducted, each further head increases the probability that the coin is the unfair one. If no tail ever appears, this probability converges to 1. But if a tail ever occurs, the probability that the coin is unfair immediately goes to 0 and stays at 0 permanently.
Susan assumes the stranger chose a fair coin (so the prior probability that the tossed coin is the unfair coin is 0). Consequently, Susan calculates the probability that three (or any number of consecutive heads) were tossed with the unfair coin must be 0; if still more heads are thrown, Susan does not change her probability. Tim and Susan's probabilities do not converge as more and more heads are thrown."
- "Bayesian convergence". Also from Wikipedia
An example of Bayesian convergence of opinion is in Nate Silver's 2012 book The Signal and the Noise: Why so many predictions fail - but some don't. After stating, "Absolutely nothing useful is realized when one person who holds that there is a 0 (zero) percent probability of something argues against another person who holds that the probability is 100 percent", Silver describes a simulation where three investors start out with initial guesses of 10%, 50% and 90% that the stock market is in a bull market; by the end of the simulation (shown in a graph), "all of the investors conclude they are in a bull market with almost (although not exactly of course) 100 percent certainty."
Bayesian convergence in this case is simply a nicer way of expressing the likelihood swamped the priors.
- Bayesian does not explain why we would even need a prior/belief for a coin flip experiment to see the Strong Law of Large Numbers (SLLN) in action. You might have knowledge the coin comes from a mint or a magician, or you might be mistaken in your beliefs, but the data from good experiments would reveal this.
- Fisher considered the idea of a hypothesis, H0, of stars being distributed at random and say from testing this we have a very small p-value. Therefore, based on the data and assumptions, we'd reject the idea that the stars are distributed at random. However, what if H0 had a large prior probability (nevermind what that could possibly even mean)? The resulting high posteriori probability to H0 would only show a "reluctance to accept a hypothesis strongly contradicted by a test of significance". That is, Fisher was demonstrating that priors themselves can be considered hypotheses that can be rejected by the data.
- If you subscribe to subjective probability, your beliefs do not matter for large enough n.
- On a different day, a Bayesian prior might be rightfully called a bias.
- Maximum entropy (ME) is increasingly being touted as being more general than Bayes even, subsuming Bayesian analysis. However, in my opinion, maximum likelihood (MLE), generally associated with frequentist methods, in exponential family models if not others, is just equivalent to doing ME with some constraints. Also, updating probabilities via Bayes or ME always arrives in the form of convergence/likelihood dominance due to incoming data, not from any priors/beliefs.
- If there were no human, or other, brains around to observe an event with probability p, frequentist probability would still work for estimating p, but a subjective Bayesian approach wouldn't.
- Priors in the garden Consider the problem of estimating the length of a square garden which has sides of length between 1 and 5 feet, as discussed in the Palgrave Handbook of Econometrics: Volume 2: Applied Econometrics:
Based on this information, it seems "natural" to say that there is 0.5 probability that the garden has sides of length between 1 and 3 feet. Equivalently, the information could be cast as saying that the area of the garden is between 1 and 25 square feet. In that case, it would appear just as natural to say that the probability is 0.5 that the area of the garden is between 1 and 13 square feet. This natural assignment of probability, however, implies that the probability is 0.5 that the length of the sides is between 1 and approximately 3.61 feet (131/2). However, it would be personally inconsistent to believe both claims and there is no principled method to reconcile the two different priors.
- The article Possible Solution to Publication Bias Through Bayesian Statistics, Including Proper Null Hypothesis Testing by Konijn et al discusses "BF-hacking".
- Bayesian statisticians can tweak their priors until convergence and other criteria look good. Is this tweaking accounted for? Is this even still doing Bayesian statistics?
- Bayesian statistics does not tell you specifically how to select a prior for all situations. The issue gets very complex in multidimensional settings, as well as trying to select a prior that is good for many parameters.
- Bayesians are hypocritical in being overly pessimistic with their prior on frequentism as a whole, given frequentism's use in advancing science over time. That is, their prior on frequentism is oddly more based on 'people don't understand it' more than 'it has advanced science'.
- Why the world need not be Bayesian after all In Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort, they note
As we have explained and advocated in our book, however, there is an alternative route to deriving and displaying such probabilitity distributions, but outside the Bayesian framework. The confidence distributions and confidence curves we have developed and investigated are free from the philosophical, mathematical and practical difficulties of putting up probability distributions for unknown parameters. Our view might not be quite as terse as that formulated by Fraser (2011, p. 329), in his rejoinder to his Statistical Science discussants: "And any serious mathematician would surely ask how you could use a lemma with one premise missing by making up an ingredient and thinking that the conclusions of the lemma were still available." The point remains, however, that the Bayesians own no copyright to producing distributions for parameters of interest given the data, and that our frequentist-Fisherian approach offers precisely such distributions, also, we would argue, with few philosophical and interpretational obstacles.
...
Some might be tempted to argue that the path with the fewer philosophical and practical obstacles should be chosen, in cases where parallel strategies lead to similar results.
...
There are also situations where the confidence distribution view leads to clearer and less biased results that what standard Bayes leads to, as with the length problem and Neyman-Scott situation.
...
In complex models, there might be distributional information available for some of the parameters, but not for all. The Bayesian is then stuck, or she has to construct priors. The frequentist will, however, not have principle problems in such situations.
...
In general, the frequentist approach is less dependent on subjective input to the analysis than the Bayesian approach. But if subjective input is needed, it can readily be incorporated (as a penalising term in the likelihood).
...
To obtain frequentist unbiasedness, the Bayesian will have to choose her priors with unbiasedness in mind. Is she then a Bayesian?
- Several things with "Bayes" in the name, or strongly associated with Bayesian statistics, are in fact frequentist things. Some examples: Bayes theorem (for simple events), naive Bayes, empirical Bayes, and MCMC.
- Simulations can give slightly different answers unless the seed for the pseudo random number generator is fixed. This could be seen as contradicting the claim that Bayesian inferences are exact, since MCMC is being used to solve problems.
- Dutch book argument If people are not operating in a Bayesian manner (ie. the frequentists), the argument goes, their probability assignments are 'incoherent' and therefore others can make "Dutch book" against them, and thus they will always lose (and therefore they should presumably hold subjective Bayesian probabilities). The flaw in the Dutch book argument is that it may only be saying what you (the Bayesian) would bet against yourself. Second, the Dutch book argument depends on the assumption that all beliefs can be expressed as probability distributions, depends on the non-Bayesian's willingness to cover an unlimited number of bets, and depends on the assumption that the Bayesian's prior is proper (which is not always the case). Moreover, Eaton and Freedman in Dutch book against some 'objective' priors showed that while the Dutch book argument is often used as an argument against frequentism, it can also apply to Bayesian approaches given certain priors.
- Bayes factors vs. AIC for model selection. There is a huge philosophical difference in model selection between Bayesian and frequentist approaches. When you compare Bayes factors, you essentially assume that one of the models you are considering is the true model that generated the data (This of course contradicts the criticism of frequentism that frequentists assume a null is true, or parameters are true, with a capital T. They are true only in the sense of assumed to be true so we can provide evidence against in a modus tollens style argument. Of course if any of us really knew something was true we wouldn't need statitics in the first place), and calculate posterior "probabilities" based on that assumption. Of course, just having a ratio of hypothesis doesn't mean either hypothesis was well-tested to begin with. By contrast, the AIC assumes that reality is more complex than any of your models, and you are trying to identify the model that most efficiently captures the information in your data. In cases where the data are actually generated under a very simple model, AIC may err in favor of overly complex models. By contrast, Bayesian analyses will typically behave appropriately when the data are generated under a simple model, but may be unpredictable when data are generated by processes that are not considered by any of the models. And the usual caveat applies that model selection is often very sensitive to the choice of priors.
- If frequentism is flawed, why do Bayesians use histograms (graphs of frequencies, probability distributions for the discrete case)? Also, why would Bayesians use probability distributions (arguably the hypothetical limit of a histogram)? On the contrary, it seems frequencies are fundamental to learning about the world.
- Two people using the same data and likelihood, but even slightly different priors, can reach different conclusions (same argument applies for potentially n people). Why should personal belief matter more than data?
- Bayesian use of priors or updating does not prevent against poor assumptions and models. Bayesian statistics is not the right tool for every job, and using Bayesian analysis does not automatically make you right. In Constraints versus Priors notes that this could be "quantifauxcation" in some cases. That is, computing/assigning a number to something and then concluding that because the result is quantitative it must have meaning, or if a Bayesian CI has smaller width it must be more meaningful.
- Is a Bayes Theorem with a subjective prior a Drake Equation type of thing? That is, the equation is "correct", but you can change the inputs to get whatever output you want. The Bayesian "probability" in these cases is literally pulled from their posterior, if you catch my meaning.
- Bayesian analyses that are not simple rely exclusively on MCMC with possibly no way to verify your results analytically.
- Every analysis relying on Bayesian statistics automatically requires a sensitivity analysis on the priors (and often these needed analyses are not done). See, for example, Assessing Bayes factor surfaces using interactive visualization and computer surrogate modeling by Franck and Gramacy, showing that Bayes factors are extremely sensitive to choice of parameters.
- In A Systematic Review of Bayesian Articles in Psychology: The Last 25 Years by van de Schoot et al, the popularity of Bayesian analysis has increased since 1990 in psychology articles. However, quantity is not necessarily quality, and they write
"...31.1% of the articles did not even discuss the priors implemented"
Because Bayesian analysis is "brittle" and often highly dependent on the priors, and no one can replicate your work if you don't detail your priors, these practices are very worrying.
...
"Another 24% of the articles discussed the prior superficially, but did not provide enough information to reproduce the prior settings..."
...
"The discussion about the level of informativeness of the prior varied article-by-article and was only reported in 56.4% of the articles. It appears that definitions categorizing "informative," "mildly/weakly informative," and "noninformative" priors is not a settled issue."
...
"Some level of informative priors was used in 26.7% of the empirical articles. For these articles we feel it is important to report on the source of where the prior information came from. Therefore, it is striking that 34.1% of these articles did not report any information about the source of the prior."
...
"Based on the wording used by the original authors of the articles, as reported above 30 empirical regression-based articles used an informative prior. Of those, 12 (40%) reported a sensitivity analysis; only three of these articles fully described the sensitivity analysis in their articles (see, e.g., Gajewski et al., 2012; Matzke et al., 2015). Out of the 64 articles that used uninformative priors, 12 (18.8%) articles reported a sensitivity analysis. Of the 73 articles that did not specify the informativeness of their priors, three (4.1%) articles reported that they performed a sensitivity analysis, although none fully described it." - Analysis for large and small sample proceeds the same, which is consistent, but mistaken. It is known that priors are even more influential with small samples.
- Bayesians often talk about "the" prior, paradoxically adding over-certainty (that it is "the" prior) to their uncertainty.
- Bayesian melding In Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort, they write
A problem that might occur in a Bayesian analysis is that there sometimes are several independent sources of information on a given parameter. There might thus be several independent prior distributions for the parameter. The Bayesian method is based on one and only one joint prior distribution for the vector of parameters, and the set of independent priors would thus need to be amalgamted into one distribution before Bayes' lemma can be applied. With two prior densities p1(θ) and p2(θ) Poole and Raftery (2000) put them together by p(θ)=k(α)p1(θ)αp2(θ)1-α where k(α) is a normalising constant and 0<α<1 gives weight to the priors. They call this Bayesian melding. If the two priors are identical, the melded version is equal to both. In Bayesian melding there is thus no information gain from having two independent prior distributions for a parameter. If, however, the independent prior distributions were represented by likelihoods L1 and L2 the pooled information is represented by L1(θ)L2(θ). Then the pooled likelihood is more informative than each of its parts, not the least when they are identical.
- Problems with the Bayesian "catchall hypothesis". In Statistical Inference as Severe Testing: How to Get Beyond the Statistics Wars by Mayo, she has some interesting quotes on problems with the Bayesian catchall hypothesis; the first by John Nelder and the second by David Sprott
John Nelder: Statistical science is not just about the study of uncertainty, but rather deals with inferences about scientific theories from uncertain data...[Theories] are essentially open ended; at any time someone may come along and produce a new theory outside the current set. This contrasts with probability, where to calculate a specific probability it is necessary to have a bounded universe of possibilities over which the probabilities are defined. When there is intrinsic open-endedness it is not enough to have a residual class of all the theories that I have not thought of yet [the catchall]."
David Sprott: Bayes Theorem requires that all possibilities H1, H2, ..., Hk be specified in advance, along with their prior probabilities. Any new, hitherto unthought of hypothesis or concept H will necessarily have zero prior probability. From Bayes's Theorem, H will then always have a zero posterior probability no matter how strong the empirical evidence in favour of H.
Another quote, from George Box is
Why can't all criticism be done using Bayes posterior analysis...? The difficulty with this approach is that by supposing all possible sets of assumptions known a priori, it discredits the possibility of new discovery. But new discovery is, after all, the most important object of the scientific process.
- No deep distinctions between statistics and parameters, priors and likelihoods, and fixed and random effects. And yes, I "get" that Bayesians view this as strength rather than a weakness.
- Priors can misrepresent opinion as experiment, and vice a versa. Lecam writes
"Thus if we follow the theory and communicate to another person a density C*θ100*(1-θ)100 this person has no way of knowing whether (1) an experiment with 200 trials has taken place or (2) no experiment took place and this is simply an a priori expression of opinion. Since some of us would argue that the case with 200 trials is more "reliable" than the other, something is missing in the transmission of information."
A prior can be misleading because it comes from previous research that is tainted with publication bias.
Statistician Allen Pannell has discussed Perioperative haemodynamic therapy for major gastrointestinal surgery: the effect of a Bayesian approach to interpreting the findings of a randomised controlled trial, by Ryan et al. Pannell notes that their Bayesian approach of using a beta conjugate prior is simply equivalent to adding a certain number of patients to the trial before the start and analyzing the resulting dataset using standard frequentist methods. In light of this fact, the use of a prior then "blessing" Bayesians to talk about probability claims, yet frequentists are denied this, therefore doesn't make much sense. Additionally, Pannell notes that the more assumptions used, especially in Bayesian statistics, will tend to lead to tighter intervals, which is not evidence of Bayesian being inherently better just because intervals are tighter.
Some, like García-Peréz, in Bayesian Estimation with Informative Priors is Indistinguishable from Data Falsification have gone further to say (bolding mine) that
"Criticism of null hypothesis significance testing, confidence intervals, and frequentist statistics in general has evolved into advocacy of Bayesian analyses with informative priors for strong inference. This paper shows that Bayesian analysis with informative priors is formally equivalent to data falsification because the information carried by the prior can be expressed as the addition of fabricated observations whose statistical characteristics are determined by the parameters of the prior. This property of informative priors makes clear that only the use of non-informative, uniform priors in all types of Bayesian analyses is compatible with standards of research integrity. At the same time, though, Bayesian estimation with uniform priors yields point and interval estimates that are identical or nearly identical to those obtained with frequentist methods. At a qualitative level, frequentist and Bayesian outcomes have different interpretations but they are interchangeable when uniform priors are used. Yet, Bayesian interpretations require either the assumption that population parameters are random variables (which they are not) or an explicit acknowledgment that the posterior distribution (which is thus identical to the likelihood function except for a scale factor) only expresses the researcher's beliefs and not any information about the parameter of concern."
A counterpoint to García-Peréz's point is that it also then follows from the paper that within frequentist methods, using regularization may also be seen as data falsification. For example, it is known that L1 regularization (LASSO) is equivalent to using a Laplacean prior, and L2 regularization (ridge regression) is equivalent to using a Gaussian prior. Note that a mathematical equivalence between these regularizations and priors might only apply in simple settings (like linear regression). However, constraints and penalties have drastically different motivations and interpretations than probability distributions. Bayesians can also use a variety of priors and don't need to rely so much on priors that are equivalent to L1 or L2 penalties. Likewise, frequentists can use a variety of regularization methods.
- Bartlett paradox. If a prior is flat on an infinite-volume parameter manifold, this scenario always favors the smaller model. At first this seems like a sensible application of Occam's Razor, but the paradox is that this happens regardless of the goodness of fit. See The Lindley paradox: the loss of resolution in Bayesian inference by LaMont and Wiggins for a good discussion of the Lindley and Bartlett paradoxes and related issues.
Lovric in his JSM 2021 presentation "On the Final Solution of the Jeffreys-Lindley Paradox", discussed moving from a testing a point null to testing H0: |θ-θ0| ≤ δ vs. H1: |θ-θ0| > δ. This, as well as focusing on practical significance and one-sided tests, dissolves the paradox. Lovric writes
"We regard that this new paradigm will not only eradicate most of the objections against frequentist testing and breathe a new life into them, but also..."
- Bayesian tests can go wrong if you pick inappropriate priors. From Lindley, X|μ~ N(μ,1). The test is H0: μ=0 vs. Ha: μ>0. The priors on the parameter really don't matter, but say Pr(μ=0)=.50 and Pr(μ>0)=.50. In an attempt to use a noninformative prior, take the density of μ given μ>0 to be flat on the half line. Note that this in an improper prior, but similar proper priors lead to similar results. The Bayesian test compares the density of the data X under H0 to the average density of the data under Ha. The average density under the alternative makes any X you could possibly see infinitely more probable to have come from the null distribution than the alternative. Thus, anything you could possibly see will cause you to accept μ=0. Effectively, all the probability is placed on unreasonably large values of μ so by comparison μ=0 always looks reasonable.
- Shrinkage estimators can not be ideal, if they are pulling back the most uncertain estimates back, "hiding" the prior performance.
- If a Bayesian CI gives a smaller interval than a frequentist CI, this is not impressive if the prior is specified in a tight range to begin with and/or more assumptions/constraints are being used. This is doing the opposite of "embracing uncertainty" as is often claimed that Bayesian methods are doing because they use priors.
- If the Bayesian reasoning 'we know X goes from a to b and cannot go to c, so the prior is from a to b' is used, I'd reply with 'the data will tell us if X can go to c or not, not any beliefs'.
- Probabilism Probability by itself is not complete. Reporting that one hypothesis is more likely than another does not falsify anything. Reporting a probability P(E) for an event E, does not mean E has been well-tested. Over-focusing on probability makes you a "probabilist" or a "Bayesian maximalist", when it is not always the right summary or tool for the job.
- Bayesians also treat parameters as fixed constants at 'the end' of their prior development. For example, the parameters in a prior's hyperparameters.
- Optional stopping, or multiplicities in general, can be an issue for Bayesians (as well as frequentists), but Bayesians often claim it is not an issue.
- Gelman has noted that
"Bayesians have sometimes taken the position that their models should not be externally questioned because they represent subjective belief or personal probability. The problem with this view is that, if you could in general express your knowledge in a subjective prior, you wouldn't need formal Bayesian statistics at all: you could just look at your data and write your subjective posterior distribution."
- Are Bayesian statistics conferences and societies safe for women? These experiences are totally heartbreaking and disgusting. I understand, obviously, that the vast majority of Bayesians are not like this, as well as there are probably some frequentist creeps out there. However, this is a concrete example that happened. Please read this post by Lum, and also this disturbing article. These articles have the following quotes:
"...a band performing at the closing party made jokes about sexual assault. This is a band that is composed mostly of famous academics in machine learning and statistics..."
...
"At ISBA 2010 (the same conference where the comments were made about my dress) [the International Society for Bayesian Analysis - J], I saw and experienced things that, in retrospect, were instrumental in my decision to (mostly) leave the field."
...
"There really is just a lot of sexual harassment of women in Bayesian statistics and machine learning..."
...
"The researchers involved are experts in Bayesian statistics, which underpins a powerful type of AI known as machine learning. The accusations have surfaced during a growing debate over the lack of diversity among machine learning researchers..." - See this article on "Bayesian probability implicated in some mental disorders".
- Bayesian priors can yield results reflecting not just an investigators's beliefs but also financial, political, or religious bias and motivations. Things like this could be damaging to science and society.
- Bayesian methods can actually be worse compared to frequentist solutions for small samples. See On Using Bayesian Methods to Address Small Sample Problems by McNeish. From the abstract (bolding is mine)
As Bayesian methods continue to grow in accessibility and popularity, more empirical studies are turning to Bayesian methods to model small sample data. Bayesian methods do not rely on asympotics, a property that can be a hindrance when employing frequentist methods in small sample contexts. Although Bayesian methods are better equipped to model data with small sample sizes, estimates are highly sensitive to the specification of the prior distribution. If this aspect is not heeded, Bayesian estimates can actually be worse than frequentist methods, especially if frequentist small sample corrections are utilized. We show with illustrative simulations and applied examples that relying on software defaults or diffuse priors with small samples can yield more biased estimates than frequentist methods. We discuss conditions that need to be met if researchers want to responsibly harness the advantages that Bayesian methods offer for small sample problems as well as leading small sample frequentist methods.
- There is one type of frequentism but many different types of Bayesian (usually based on how you get the priors) and some in-fighting among them. Are you "empirical", "subjective", "objective", or something else? Do you not look at the data before making the prior, or do you constantly fiddle with and change the prior until it makes diagnostics "looks good"? Probably joking a little, Good notes that there are quite a few varieties of Bayesian.
- Dempster's rule is not free of contraintuitive results. Consider an example with three suspects Ω={a,b,c} from Zadeh (1984) discussed in Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort
Witness 1 has the masses .99, .01, 0, for these respectively, while witness 2 has masses 0, .01, .99. Dempster's rule combines these two sources of evidence to full certainty that b is the guilty one despite both witnesses having very low belief in this statement. Incidentally, the Bayesian would come to the same contraintuitive conclusion if she combined the two distribution by Bayes' formula. So would the statisticians using the likelihood in the way Edwards or Royall suggested.. For Dempster, Bayes and the likelihoodist, replacing the zero by only a small amount of belief for each witness would remove the difficulty.
- Noninformativity is a difficult notion in the Bayesian paradigm In Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort, they write
The method of inverse probability was the Bayesian method with flat priors to reflect absence of prior information. Flatness of a probability function is, however, not an invariant property. If you know nothing of ψ you know nothing of θ=t(ψ) when t is a monotone transformation, and the prior density for θ will not be flat if the transformation is nonlinear and the prior for ψ is flat. This problem of noninformativity was Fisher's basic motivation for inventing the fiducial distribution in 1930. In a Fisherian analysis, noninformativity is represented by a flat prior likelihood, or equivalently, with no prior likelihood. Because the likelihoods are invariant to parameter transformations, noninformativity is an invariant property of prior likelihoods.
- Despite Bayesian insistence on inference not depending on counterfactual reasoning, Bayesians are interested in such issues during the experimental design stage, which is inconsistent.
- Proofs of God existing, the resurrection of Jesus, and other miracles, rely on Bayesian statistics. Who is anyone to tell you that your subjective prior beliefs are wrong?
- Bayesian work has tended to focus on coherence. The problem with pure coherence is that one can be coherent and be completely wrong. Additionally, for Bayesians to learn from error, they must violate Bayesian coherence and reject the idea of learning by Bayesian updating, as there is no way to list all possibilities Hi as Bayesian coherence requires. The tools that frequentists use have an advantage in that they don't need to wait for a hypothesis to get a low probability before trying new conjectures.
- False confidence theorem. Balch, Martin, and Ferson in their Satellite Conjunction Analysis and the False Confidence Theorem, discuss that there are
probabilistic representations of statistical inference, in which there are propositions that will consistently be assigned a high degree of belief, regardless of whether or not they are true.
In their work, using those modes of statistical inference could result in probability dilution and false confidence, that is, a severe underestimate of satellite collision risk exposure, or a high confidence that their satellites are safe whether or not they really are safe. This occurs regardless of the validity of the mathematics. In other words, it is more a mismatch between the mathematics of probability theory and the uncertainty or subject matter to which it is applied. The false confidence theorem shows that all epistemic probability distributions (which includes Bayesian) suffer from arbitrarily severe false confidence.
Thus, our goal has been to help satellite operators identify tools adequate for limiting the literal frequency with which collisions involving operational satellites occur. Framing the problem in frequentist terms enables us to do that, whereas framing the problem in Bayesian terms would not.
Interestingly, the size of the false confidence can "only be found for a specific proposition of interest through an interrogation of the belief assignments that will be made to it over repeated draws of the data". That is, frequentist confidence intervals and regions do not suffer from false confidence.
Also, check out An exposition of the false confidence theorem by Carmichael and Williams.
- Using asymmetric prior distributions in medicine could delay recognition of costly effects of making treatments in the unexpected direction. For example, physicians for many years have prescribed low-fiber diets for bowel problems until evidence accumulated they were more harmful than beneficial, some physical therapies can unexpectedly worsen injuries, and antibiotics have often been given for conditions that antibiotics can worsen.
- Small area estimation can be better with frequentist methods See Bayesian versus frequentist measures of error in small area estimation by Singh et al. They state that "The Bayesian methods are found to have good frequentist properties, but they can be inferior to the frequentist methods". Also see Impact of Frequentist and Bayesian Methods on Survey Sampling Practice:A Selective Appraisal by Rao. He writes "I have provided an appraisal of the role of Bayesian and frequentist methods in sample surveys. My opinion is that for domains (subpopulations) with sufficiently large samples, a traditional design-based frequentist approach that makes effective use of auxiliary information, through calibration or assistance from working models, will remain as the preferred approach in the large-scale production of official statistics from complex surveys".
- Choice of parameterizing mathematically equivalent Bayesian models issue The choice of parameterization of Bayesian models that are equivalent mathematically can affect the convergence of MCMC. That is, how you code your models and priors can affect convergence (and hence your posteriors).
- Frequentism always views data as random while a Bayesian approach correctly views data as fixed Actually, frequentist design based sampling, for example, also views data as fixed. To include a unit or not ("binary inclusion indicator") is what is random. See Sampling: Design and Analysis by Lohr.
Frequentism is really just a special case of Bayesian.
- But this contradicts the "frequentism is bad for science" critique.
- Frequentism is really just Bayesian statistics with a flat prior This is like saying
atheism is really religion but without belief. Frequentism is statistics, period. No need for
priors at all. Such priors are not solicited. Lack of priors is not a flat prior, even if mathematics may come out identical (in certain cases, or at least the decision from the analysis is in the same direction), the interpretation is not the same, nor is it needed. Additionally, frequentists can use a penalized likelihood approach, or a ridge regression approach, which get away from the Bayesian belief of frequentism only being equivalent to using a "flat prior". See Confidence, Likelihood, Probability: Statistical Inference with Confidence Distributions by Schweder and Hjort for some discussion.
Another take on this charge is, what are Bayesian problems with frequentism if that were true? You wouldn't complain frequentism is false if it is just Bayesian statistics which you hold true. The statistician Edwards said
"It is sometimes said, in defence of the Bayesian concept, that the choice of prior distribution is unimportant in practice, because it hardly influences the posterior distribution at all when there are moderate amounts of data. The less said about this 'defence' the better."
Some Bayesians saying frequentism is just Bayesian with a flat prior contradicts some Bayesians saying that Bayesian is so much more than just a likelihood and prior.
- Bayes Theorem The simple Bayes Theorem, despite the name, is fully in the frequentist statistics domain and is a basic result from the multiplication rule and conditional probability. The equation is
P(A|B) = [P(B|A)P(A)]/P(B)
where A and B are general events. Where Bayes Theorem becomes technically "Bayesian" is where the P(A) is a probability distribution for a parameter, and definitely "Bayesian" where the P(A) is based, not on prior experiment or objectivity, but on subjectivity. For a binary event, P(B) = P(B|A)P(A) + P(B|not A)P(not A). Note that the ratio often becomes computationally intractable because of very difficult integrals in the numerator and denominator. - Bayesian is just conditional probability, nothing more, nothing less. The standard Bayes Theorem, yes, or even when the prior is based on a lot of frequency data. However, when the prior is subjective, or the sample size is very small, or it has poor frequentist properties, I do not believe it is justified to be called "probability". Otherwise you might have to accept absurdities like the Bayesian proofs of God, for example, as "probability" just because they go through the process and are a number between 0 and 1 that satisfy the axioms. Being able to compute a probability for a hypothesis does not mean that the hypothesis was well-tested.
- Frequentists are hypocrites because of latent variable models! For example, in Latent Variable Models and Factor Analysis: A Unified Approach by Bartholomew et al,

It is claimed by critics that this is a frequentist text and that therefore frequentists have cognitive dissonance and frequentists will complain about the prior of other people's Bayesian analyses, yet they are happy to apply latent variable models, stating that the results don't depend on the prior. In actuality, this text has pages on Bayesian analysis. Also, there are times where priors strongly influence a Bayesian analysis, for example where there is not a lot of data, so frequentists "complaining" is certainly justified in those cases. Bartholomew makes the point that
The link between the two is expressed by the distribution of x given w [I changed his symbol to w. -J]. Frequentist inference treats w as fixed; Bayesian inference treats w as a random variable. In latent variables analysis we may think of x as partitioned into two parts x and y where x is observed and y, the latent variable, is not observed. Formally then, we have a standard inference problem in which some of the variables are missing. The model will have to begin with the distribution of x given w and y. A purely frequentist approach would treat w and y as parameters whereas the Bayesian would need a joint prior distribution for w and y. However, there is now an intermediate position, which is more appropriate in many applications, and that is to treat y as random variable with w fixed.
That is, he is making very clear that latent variable models are some hybrid of the two approaches. He also writesThere can be no empirical justification for choosing one prior distribution for y rather than another.
This is apparently because X is sufficient for y in the Bayesian sense. In other words, if no priors matter, it is like not using a prior in the first place. - Likelihood swamps the prior It is well known that the likelihood swamps the prior as n increases, especially if it is related to effect size. There is probably more agreement on likelihood models than on priors. So if the likelihood model is a good candidate for "truth", we see Bayesian converge to frequentism as n increases, for any choice of prior, this is not a strong argument for using priors, especially when one can incorporate expert knowledge in other ways, such as experimental design, subject matter expertise, survey sampling, likelihood, etc. If priors are irrelevant for large n, then they are still irrelevant for small n, even if they have more pull. Although, for small n, as you may have expected, most frequentist and even Bayesian analyses (almost any type of analysis) are of dubious value. See A Closer Look at Han Solo Bayes.
- Bayesian model is a special case of the classical model Patriota has noted that the Bayesian model is just a special case of the more general classical model. That is, imposing a prior does not lead to a more general structure, because when you impose a rule you are restricting the mathematical structure. Patriota also proposed an s-value as an alternative to the p-value. Although he notes that finding thresholds for the s-value to decide about a H0 is still an open problem, and that the asymptotic p-value can be used to test H0. I interpret all of this to mean that the classical model and p-values are in fact doing a pretty good job.
But everything is subjective anyway!
- Everything? That is very doubtful. If "everything is subjective" is true, then the claim "everything is subjective" is itself subjective and therefore I doubt it very much. Arguably the main purpose of science is to be objective as possible.
- Frequentists are being very subjective when they choose to calculate a 95% confidence interval instead of a 90% confidence interval This is not as subjective of a choice as subjective Bayesians make it out to be. Ideally, the choice of confidence/α should be based on error, cost, subject matter expertise, and other considerations. For example, in "The Significance of Statistical Significance", Hal Switkay suggests roughly setting α based on 1/sample size. The choice of α, is not, or should not be, the statistician just willy-nilly deciding on a number. Either way, the confidence interval is a process to make intervals that capture an objective unknown constant parameter a certain percent of the time, that can, for example, easily be demonstrated to work in simulations.
- Those wanting to justify their α will always fail. The critique is that it is unclear how exactly the researcher should go about the process of justifying an α. In The fallacy of the null-hypothesis significance test Rozeboom wrote
"Now surely the degree to which a datum corroborates or impugns a proposition should be independent of the datum-assessor's personal temerity. Yet according to orthodox significance-test procedure, whether or not a given experimental outcome supports or disconfirms the hypothesis in question depends crucially upon the assessor's tolerance for Type I risk."
α is the probability of making a Type I error. Statisticians should therefore make α directly tied to the cost of making a Type I error (and then further adjust α smaller if needed). This cost can be an actual dollar amount, lives lost, or the general cost of "if the claim being tested were true, how would that disrupt our current understanding of the world?", for example, in the case of testing claims of ESP. Moreover, Rozeboom presumably has no problems with using "personal temerity" in choosing a prior distribution. - Justifying an α "does not turn weak evidence into strong evidence". If each of three people conduct the same test on the same data and coincidentally each get p-value = .047, but their αs were .05, .10, and .001, respectively, this is breaking the rules by supposedly turning weak evidence into strong evidence. However, it is clear that the evidence remains weak in each case. All this critique really shows is that the Bayesian bad habit of relying on unchecked subjectivity ("personal temerity") to set α can be remedied by objective frequentism standards (cost of making Type I error) to set α. Such criticisms tend to completely ignore notions of replication of experiments, as well as ignore similar "cutoff" issues if Bayes Factors, or any other statistic, were to be used instead of p-values to denote something like "statistical significance".
- Asking me to set α so you can make a decision means your conclusion would depend on my criterion. If so, isn't that weird, because my criterion didn't influence the evidence, right? The criterion didn't influence the evidence, but it can influence the decision. A decision depends on evidence and criteria. The decision to bring an umbrella depends on the amount of rain and one's tolerance or cost for getting wet. Ideally α should be set based on the cost of making a Type I error and/or sample size, and not on arbitrary and completely subjective beliefs. The article "Setting an Optimal Alpha That Minimizes Errors in Null Hypothesis Significance Tests" by Mudge et al discusses a more intelligent way to set α.
- Everyone makes assumptions and us Bayesians at least make our assumptions explicit
Frequentists do too, they spell out assumptions in detail as well. Consider a possible Bayesian response
Ever hear a frequentist call their stats "subjective?" Some frequentism popularizers even have the audacity to teach that the main difference between Bayes and Frequentist is that Bayesian is subjective and frequentism is objective.
If everything is supposedly subjective, why the label in the first place? Why is there a separate 'subjective Bayesian' term created by Bayesians? Obviously the subjective part refers to the priors and not anything else, like taking previous experiments into account, likelihoods, expert opinion, etc. Anyone can flip a coin and observe the relative frequency of Heads tending to converge to a horizontal line as the number of flips increase, or the ball bearings cascade down a Galton board to form an approximate normal distribution, and are therefore not subjective. - Passing the buck on subjectivity Using experts to back up subjective priors doesn't solve the problem of subjectivity. Are you using experts (and hence priors) from the plaintiff or the defendant?
- Don't critique us Bayesians for using priors since frequentists use background knowledge all the time Scientists of all stripes are always permitted to use knowledge of things, experimental design, results from previous experiments, subject matter expertise, logic, scientific knowledge, penalized likelihood, direction of statistical tests, etc. See, for example, Prior Information in Frequentist Research Designs and Social (Non-epistemic) Influences: The Case of Neyman's Sampling Theory by Kubiak and Kawalec, showing that "priors", in the loose sense of background knowledge, are used in frequentism (or other other area of study, I'd imagine). Priors, however, in the Bayesian sense, are very specific mathematical objects, and that is what is being referred to. To compare using Bayesian priors, which are putting possibly subjective probability distributions on parameters to using any inputs for an analysis and saying "well, both are the same thing really" is simply mistaken.
- Bayesian can take expert opinion into account using the prior It can also take
personal beliefs into account that can vary from person to person. Do the good and bad cancel out?
Frequentism can take expert opinion, background knowledge, and results from experiments into account as well, just not using
priors. There is obviously some subjectivity in choice of models, analysis, significance level, etc.
If testing claims of ESP, consider lowering α drastically because it is an extraordinary claim that, if true, would change our fundamental knowledge about the world. The James Randi Educational Foundation had a $1,000,000 challenge to anyone demonstrating ESP, psychic, paranormal, etc., powers in a controlled setting, and they took this approach. Suffices to say, using good experimental design and low α precluded winning the money merely by chance. The JREF rightly recognized that setting α should be based on cost of making a Type 1 error.
Here is some "expert opinion" that led to Bayesian proofs of God existing: The Probability of God: A Simple Calculation That Proves the Ultimate Truth by Unwin, and The Existence of God by Swinburne.
- Bayesians are more honest than frequentists Presumably because of making assumptions explicit. However, this is just opinion/experience, and has no bearing on the mathematical theory. As mentioned, frequentists do make their assumptions known.
- Don't get hung up on models Like Gelman writes at his blog Statistical Modeling, Causal Inference, and Social Science, we
use models and to not get hung up on the models, and to check them (mostly using frequentist
concepts), iterate, etc. However, I believe while we all use models, stuff like priors are
different than other models since they literally can be anything, while likelihood models are more
agreed upon and "constrained", for lack of a better word. For example, see Golf Putting Models. I know how to
interpret a logistic regression, how to extend it for more predictors, and so on. How do I do that
with Gelman's (sensible, mind you) unique model? How do I compare everything about his model with
models others could use to analyze this putting data? It isn't really clear statistically how to do
that, and surely a simple "fit" may not be the best way to decide the winner.
Of course, this contradicts the "all null models are actually false" charge.
- Mathematics based on subjectivity is not well-defined A Bayesian approach does not, or cannot, give a full account of the "mathematical rules of engagement" for working with subjective quantities. Simply put, just because a number is between 0 and 1 and one feels it is a probability does not mean it is a probability properly defined. Probably most frequentists are fine with it being "chance", "uncertainty", "personal belief", however.
Wasserman has noted that we all use p(X) for probability, but maybe should use f(X) for frequencies and b(X) for beliefs/Bayesian.
- Frequentist statistics tries to make the world a correct place. It is objective. Bayesian Statistics tries to make the world a better place. It is subjective. This contradicts the "Some frequentism popularizers even have the audacity to teach that the main difference between Bayes and Frequentist is that Bayesian is subjective and frequentism is objective" charge. There are many similar sayings I've come across in looking at critiques of frequentism. So while this was meant to be another "funny" one, I'll respond seriously. Much "frequentism" has made and continues to make the world better. Studies showing smoking is bad, risk factors for CHD, numerous sample surveys informing people, enjoyment of games of chance, experimental design for science, weather prediction, benefits of randomization, etc. As mentioned before, also see The Lady Tasting Tea: How Statistics Revolutionized Science in the Twentieth Century by Salsburg. I personally do not believe that extreme forms of subjectivity have ever been aligned with good scientific practice.
What is your background?
- Background B.S. Mathematics, M.S. Statistics, Mathematical Statistician for years and counting. Earned a B in Bayesian statistics (p < .0001) in grad school. Professionally I work with large sample surveys and do mainly frequentist inference. I use Bayesian methods in multiple imputation, small area estimation, and as alternatives to frequentist hypothesis testing if needed. I tend to use machine learning for real-time predictions based on a variety of competing models and finding groups in data (although there is a lot of overlap with what I would call regular ol' statistics).
Thanks for reading and sending in comments/corrections! Remember,
- Prior, prior, chance on fire!
- Those who do not learn frequentism are doomed to repeat it
- I'm a Banoian
Comment from reader:
I got many answers in the frequentist vs. Bayesian thread, but this pro-frequentist page is really superb!
Disclaimer
Views expressed here are only the personal opinions of the author, and not those of any organization he is associated with.
Please anonymously VOTE on the content you have just read:
Like:Dislike: