Frequentism is Good
10/10/17
Here is a response I wrote to an article that appeared in the October 2017 issue of the Significance magazine, a magazine which I really enjoy. Thank you Significance editors for also making several minor, but needed, edits in my writing.

After reading "What are the odds!? The "airport fallacy" and statistical inference" by Bert Gunter and Christopher Tong (August 2017), I am curious to know what precisely they mean by "Bayesian", because there are many different types of Bayesians out there.In their article they argue that statistical inference of the frequentist variety leads science astray. I agree that frequentism is an embarrassment, but it is actually an embarrassment of riches.
Frequentism, in the most simple case in my opinion, can be understood as a coin flip experiment, keeping track of the frequency of heads. Over time, this percent (statistic) settles down into what could be considered the probability of heads (parameter) - and note that it doesn't have to be 50% either. A strong law of large numbers result says that we can get arbitrarily close to this true probability as well, given a large enough number of flips. You tell me how close you want to get and I'll tell you the expected number of flips needed. This is rigorous, like an epsilon-delta proof from calculus. It happens regardless of your brand of philosophy of statistics. Science over time is like this too.
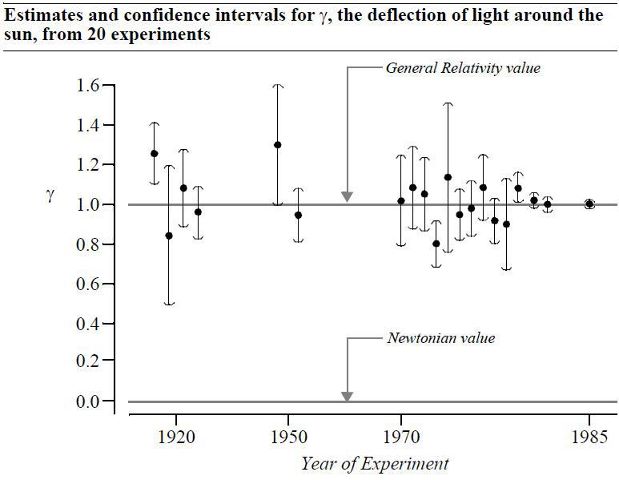
An example I remember is from the book The Statistical Sleuth, by Ramsey and Schafer (statisticalsleuth.com). They present a graph of estimates and confidence intervals for y, the deflection of light around the Sun, from 20 experiments carried out from 1919 to 1985. Each experiment in itself may have had flaws, may have not been conclusive in and of itself, may not have had ideal (whatever that means) statistical methods, but over time (again, long term frequencies), the conclusion is very clear: estimates are more centered around y = 1 (the value predicted by general relativity) and the confidence intervals are becoming smaller on average.
(I inserted this now, not in original article - JS)Gunter and Tong should also read some work by Deborah Mayo if they have not (errorstatistics.com). I admit I do not understand it all, but she argues for "severe tests" to move the discipline forward, quite the opposite of abandoning tests.
I also observe that in many cases where there is a lot of data, frequentist and Bayesian approaches do tend to be in agreement ("likelihood swamps the prior"), if not in the test statistics then at least in the decisions made from the analysis. Because of all these reasons, I simply fail to see how frequentism is a fallacy.
JS
Washington, DC
We should strive to be unapologetic frequentists. The world and science itself is very frequentist in nature and much of the good of Bayesian statistics relies on frequentist concepts (see Frequentism, or How the World Works).
Thank you for reading.
Update 1/1/18
(I did not submit the following response to the journal)
The authors responded to what I wrote in the December 2017 issue of the Significance magazine.
The authors apparently dislike that I used a coin flip experiment as an example, calling it "simplistic" (which is what I called it too). I agree it is simplistic, but this reason is why I often use it. A simple example is so one doesn't get bogged down in the details/weeds of a very specific and complex experiment. The point of this most simple example is to show that no priors are needed, or wanted, and to appeal to the Strong Law of Large Numbers which helps justify the frequentist definition of probability. You do a lot of trials and observe the result of the relative frequency of heads converging to some horizontal line ("probability of heads").
The authors talk about making a myriad of choices that can lead to flawed inference, but fail to discuss how Bayesian inference supposedly solves these problems (it doesn't), nor talk about when frequentism leads to good inference (plenty of examples - survey sampling, polling, quality control, Framingham Heart Study, studies showing smoking is bad for you, Rothamsted Experimental Station experimental design, casinos, life insurance, weather prediction (NWS MOS), lotteries, German tank problem, randomization, ecology, Bayes Theorem itself is a frequentist theorem, ...). If anything, Bayesian inferences can increase these problems, or create a different set of problems, because in addition to the usual myriad of things to choose from in any analysis, now we have an infinite number of priors we can choose from. The problem is especially bad in multidimensional settings. I do agree with them on the usefulness of pre-specification of an analysis plan. That is something which is sensible for Bayesian, frequentist, and any other, analyses.
I chose the deflection of light example (see the graph above) because it educates us all on a lot of good points. First, it shows uncertainty of each experiment/measurement with the confidence intervals. Second, it shows what competing theories predict and what we observe in reality. Last, it shows that if one interval overlaps with the "truth", or one interval doesn't overlap with the "truth", a single case is neither a success or failure in and of itself. That is, it shows long-term frequency thinking makes for good science. Put another way, each individual experiment can be thought of to be like a coin flip, with convergence to "truth" over time.
Last, regarding the "likelihood swamps the prior" issues we both discussed, I used the likelihood to emphasize the larger role of data, since the likelihood is a function of the data, while they use likelihood to emphasize the larger role of models. I argue that the choice of likelihoods are generally more agreed upon and clear cut than the choice of priors, for example. In the coin flip experiment, note that I do not need any likelihood or prior.
Thanks for reading.
Please anonymously VOTE on the content you have just read:
Like:Dislike: