Third Person Singular Pronoun Problem
5/2/19
The issue is, the English language has no agreed upon choice of pronoun for gender-neutral, third-person singular nouns that refer to people. Do we use he, she, they, it, one, thon (yes this was proposed once as "that one"), "he or she", "him or her", "his or hers", "himself or herself", "he/she", "(s)he", "s/he", "hse", "him/her", "his/her", "himself/herself" or something else? Note that besides being clunky, the writer still has the choice of which pronoun to place first in some of these variations like "him or her" or "he/she". Personally, I vote for just using "he", but I am biased, since I grew up using it and I am male, and for both of those reasons it just seems natural, even though I know it has issues. However, this is a very interesting issue that concerns fairness, bias, feminism, LGBTQ communities, non-binary gender, and has a fascinating history. Here is my statistician attempt at a solution to solve this problem two ways: randomness and symbols.
We could simply randomly select from the words {he, she} and use that method as needed throughout a document. Therefore, over time, generic "he" and "she" instances would appear with roughly equal frequency, and we eliminate bias. Because the world is digital now, and printed books are less and less, randomizing elements of a text is quite simple to do. Companies like Microsoft can add this option to Microsoft Word, for example. More on that later.
If we want to use more "she", since "he" has historically been used more, we can do that too by sampling using weights, and we would just give more weight to "she" being selected. For example, randomly sampling "she" five times more often than "he". Your vector of words to sample from would be {"he", "she", "she", "she", "she", "she"}. Of course, the opposite could be done too, for example in talking about traditionally or stereotypically female occupations like nursing.
We could also tabulate the percentage of "he" and "she" when used generically in, say, publications to gauge existing bias to help in setting how much to bias things in the fair direction moving forward. Perhaps setting the percents based on the "sex at birth ratio" for a country? Perhaps base the percents on the genders of the contributors to a publication or genders in an occupation? Not sure here, but in any case the option is easily there.
Note that we could also sample from {he, she, they}, or {he, she, they, any other option(s)} too.
Let's look at a few examples of this idea in action. You can refresh the webpage to see the changes, bolded for easy spotting.
Before (static)
- When a child goes to school, he makes new friends.
- The way a person spends his or her free time is quite telling.
- If the item is damaged, he/she can return it.
- A doctor can decide for himself if the medicine works.
- Ask a friend, and he will tell you what is on his mind.
After (dynamic)
- When a child goes to school, makes new friends.
- The way a person spends free time is quite telling.
- If the item is damaged, can return it.
- A doctor can decide for if the medicine works.
- Ask a friend, and will tell you what is on mind.
Another possible way this could be partially solved, is to use a symbol for the idea "he or she". For example, here "H" is overlayed with with "S" and "h" is overlayed with "s" (a graphic designer could make this look better). To me each looks like a "b" (for "binary"?), but with a yin-yang squiggle through it, indicating, perhaps, that the border between choices isn't so clear-cut. Or maybe I'm reading too much into it. In any case, the letters "h" in "he" and "sh" in "she" would be replaced by the symbol. How to pronounce the word would then be up to the individual reader, sort of a "fielder's choice". Then, maybe someone could extend this symbol idea to "his or her" and other situations.
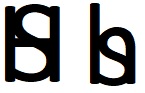
another possibility
After (symbol version)
- When a child goes to school,
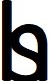 e makes new friends.
e makes new friends.
- If the item is damaged, e can return it.
Here is a Visual Basic macro I made for use (and please edit as needed) in Word. In your Word document, you'd just type a "*he" for a generic "he or she", and then run the macro for each occurrence to randomly fill in with "he" or "she".

To use the macro with the {"he", "she", "she", "she", "she", "she"} example, you'd just change the .5, or 50%, to .833 or 5/6.
Thanks for reading.
Please anonymously VOTE on the content you have just read:
Like:Dislike: