Changepoint Analysis
12/5/18
In Jason Ash's 12/5/18 article Puppy Steps, he discusses a Bayesian method for determining when the number of steps he took statistically changed. He does a Bayesian analysis to
"determine if my step behavior changed over time. Was there a specific day or range of days where my activity increased or decreased? How much did my steps change? If I observed a change, what could I attribute it to?"
In this article, I will show "frequentist" changepoint analyses that can also shed some light on these questions.
Background
In the paper changepoint: An R Package for Changepoint Analysis by Killick and Eckley, they write
"...changepoint detection is the name given to the problem of estimating the point at which the statistical properties of a sequence of observations change."
This is a great paper for the history and mathematical details of changepoint analysis, a topic which has been studied probably since the 1950s.
Exploratory Analysis
First, I convinced myself the functions are working as expected by constructing a dataset to have an obvious changepoint, like so:
- steps ~ N(mean = 9000, stddev = 2500), if date is in [7/29/18, 9/1/18]
- steps ~ N(mean = 5000, stddev = 1000), if date is in [9/2/18, 11/24/18]
After I read in the simulated data and did cpt.mean, I obtained
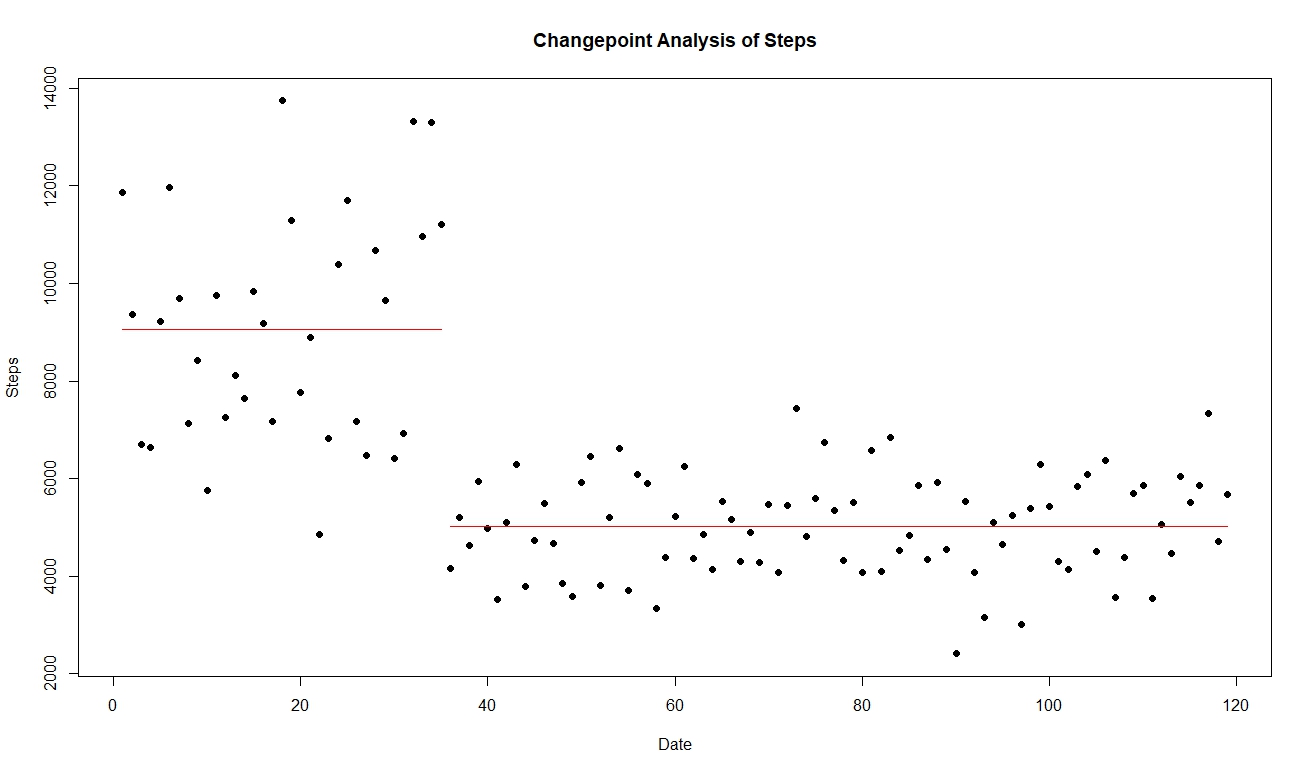
The changepoint is at observation 35, which is 9/1/2018. That is, the mean of the data from [7/29/18, 9/1/18] are statistically different from the mean of the data from [9/2/18, 11/24/18].
Next I did cpt.var, and I obtained
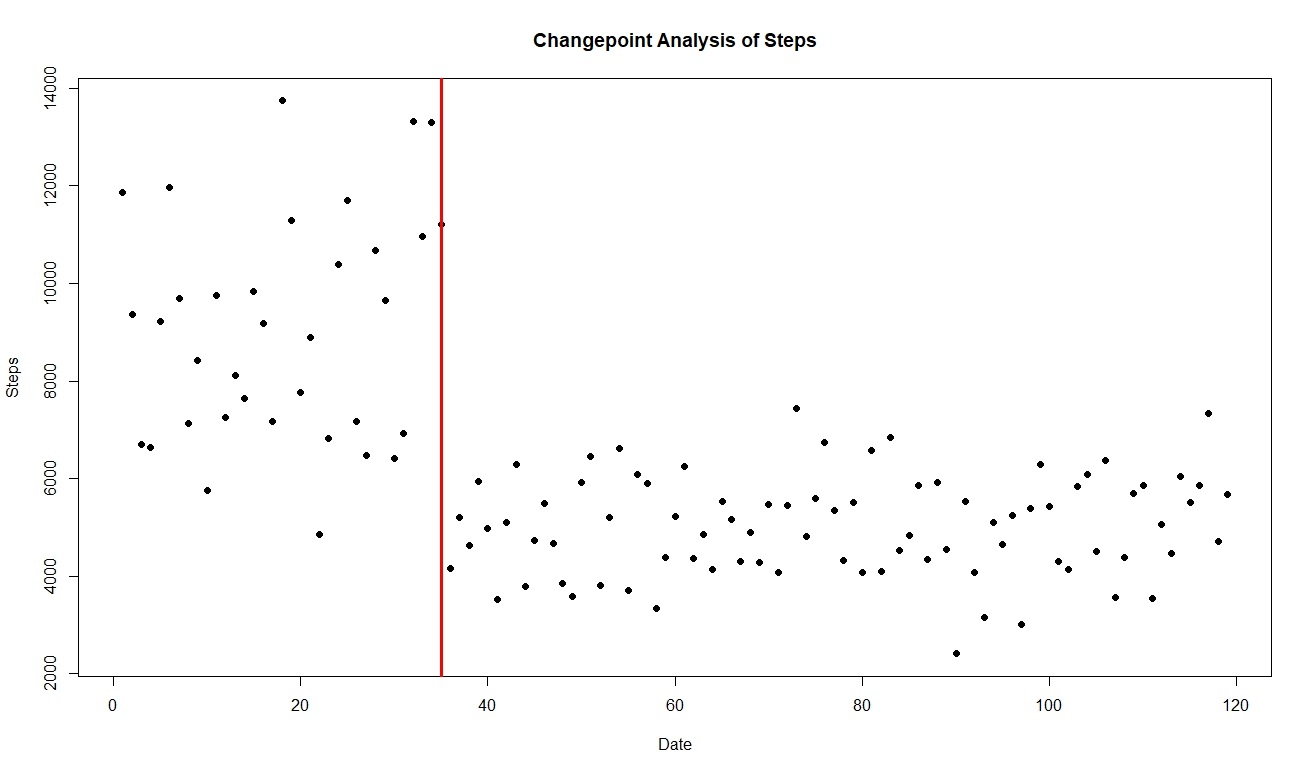
The changepoint is again at observation 35, which is 9/1/2018.
I then did cpt.meanvar, and I obtained
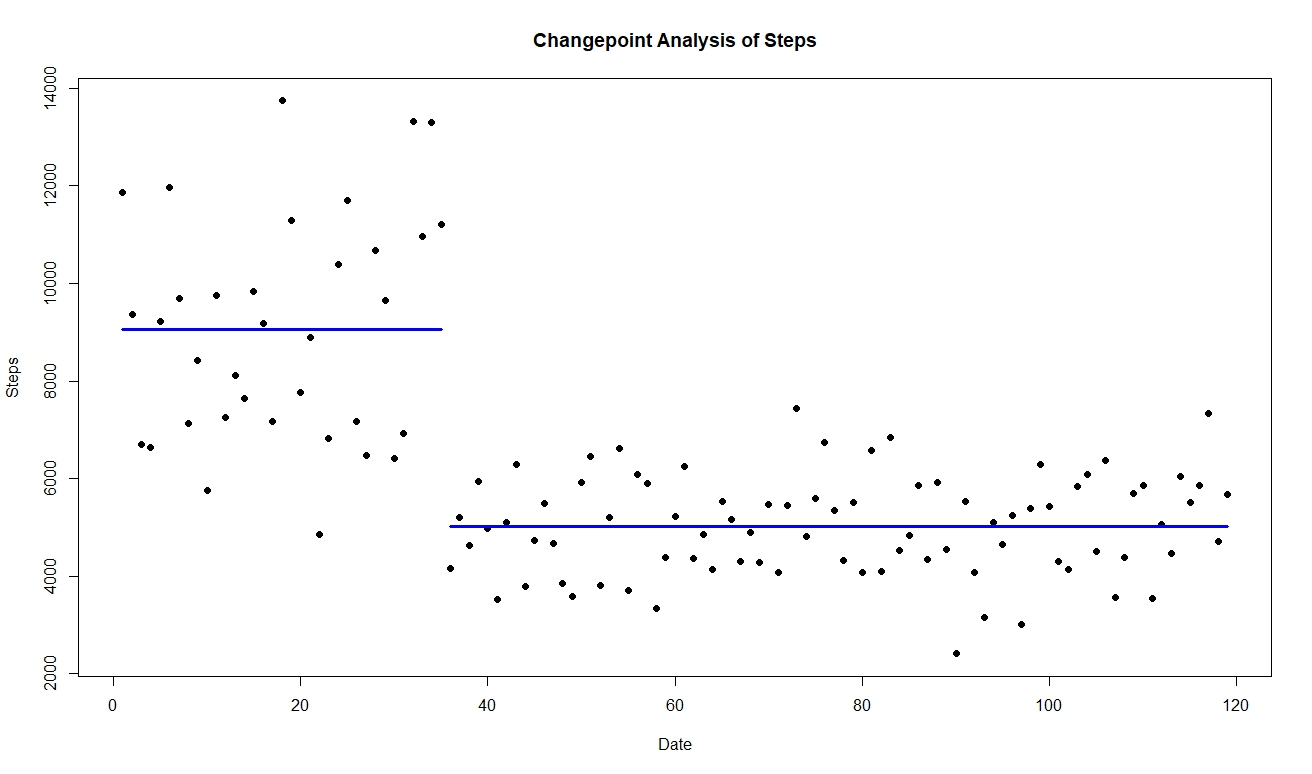
The changepoint is at 9/1/2018. In this case, mean and variance of the data from [7/29/18, 9/1/18] are statistically different from the mean and variance of the data from [9/2/18, 11/24/18].
Last, I did cpt.np, which as mentioned is the nonparametric version. I obtained
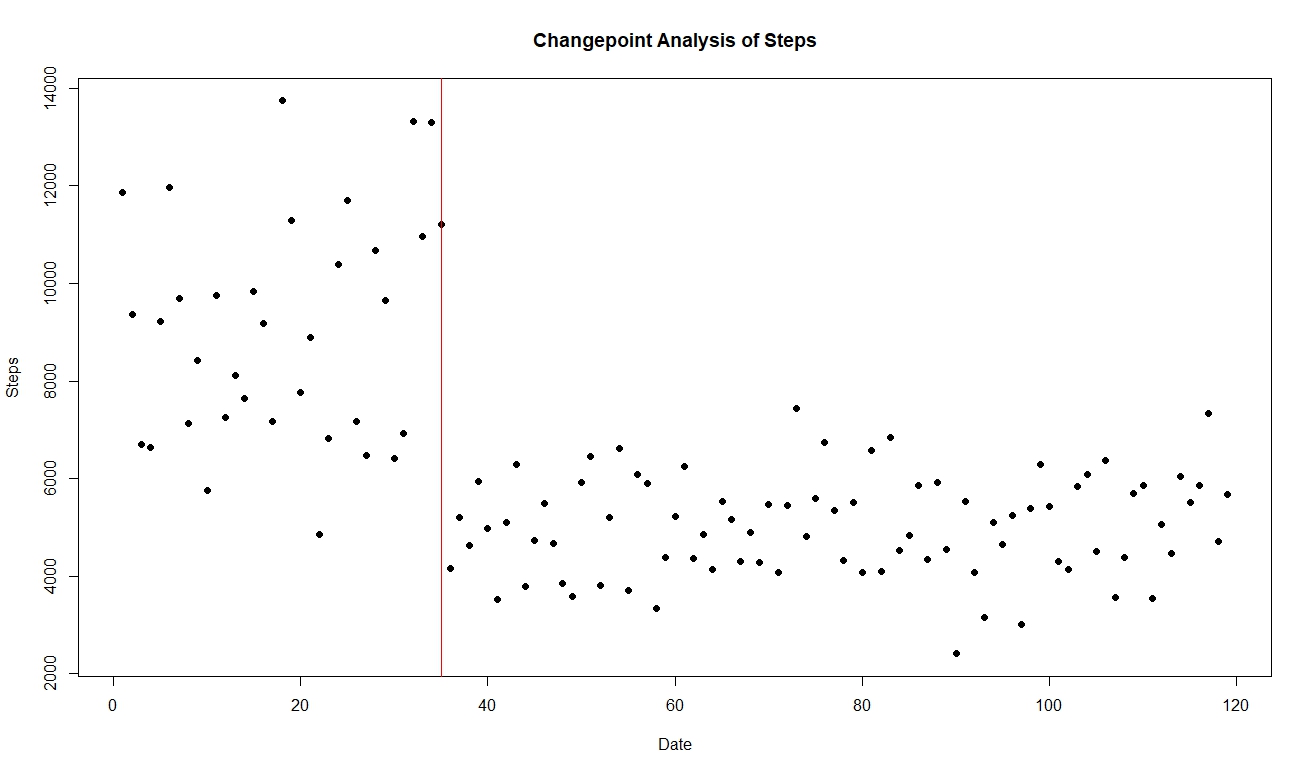
The changepoint is again at 9/1/2018.
These methods most likely all chose the same changepoint because I made the means and variances of the data before and after so much different. Also, note that the changepoint functions can also be set to detect multiple changepoints.
Now that we are convinced the changepoint functions work, let's look at Ash's actual step data.
Analysis
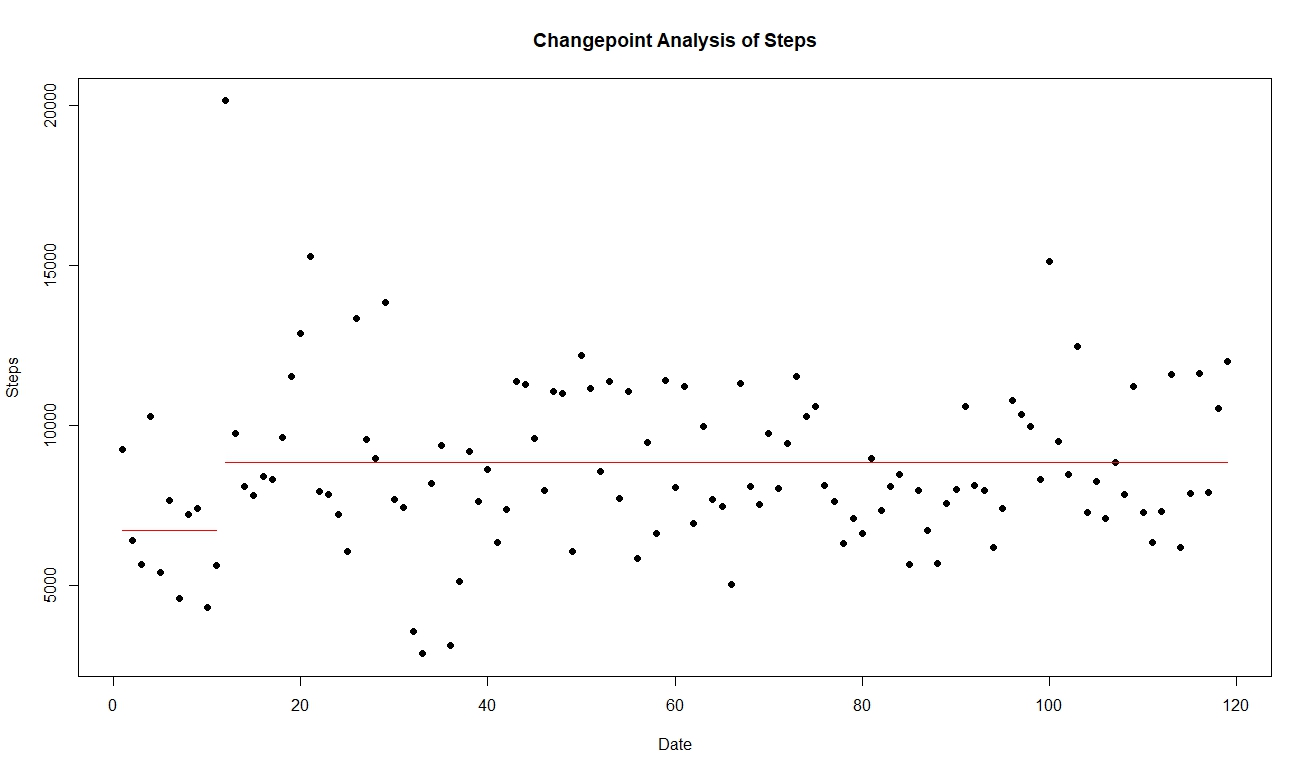
Using cpt.mean, changepoint detected at 8/8/18

Using cpt.var, changepoint detected at 9/3/18
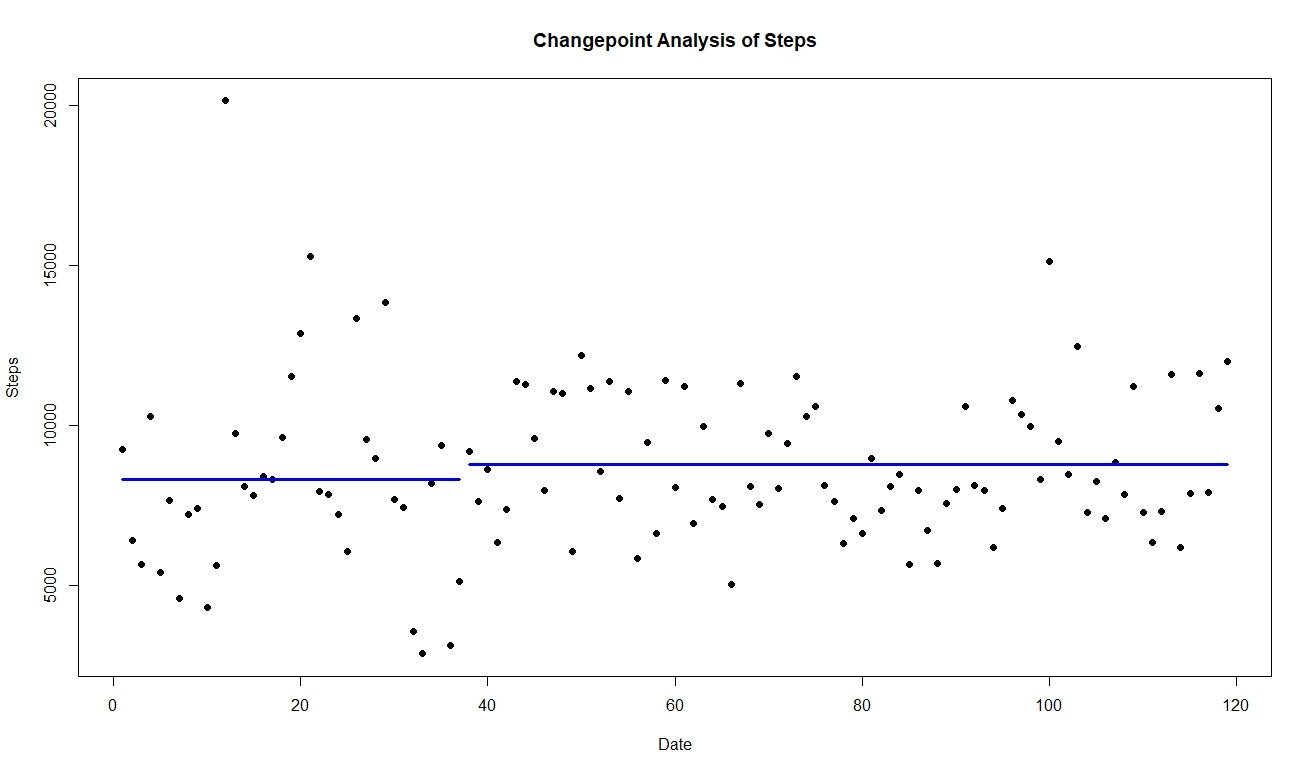
Using cpt.meanvar, changepoint detected at 9/3/18
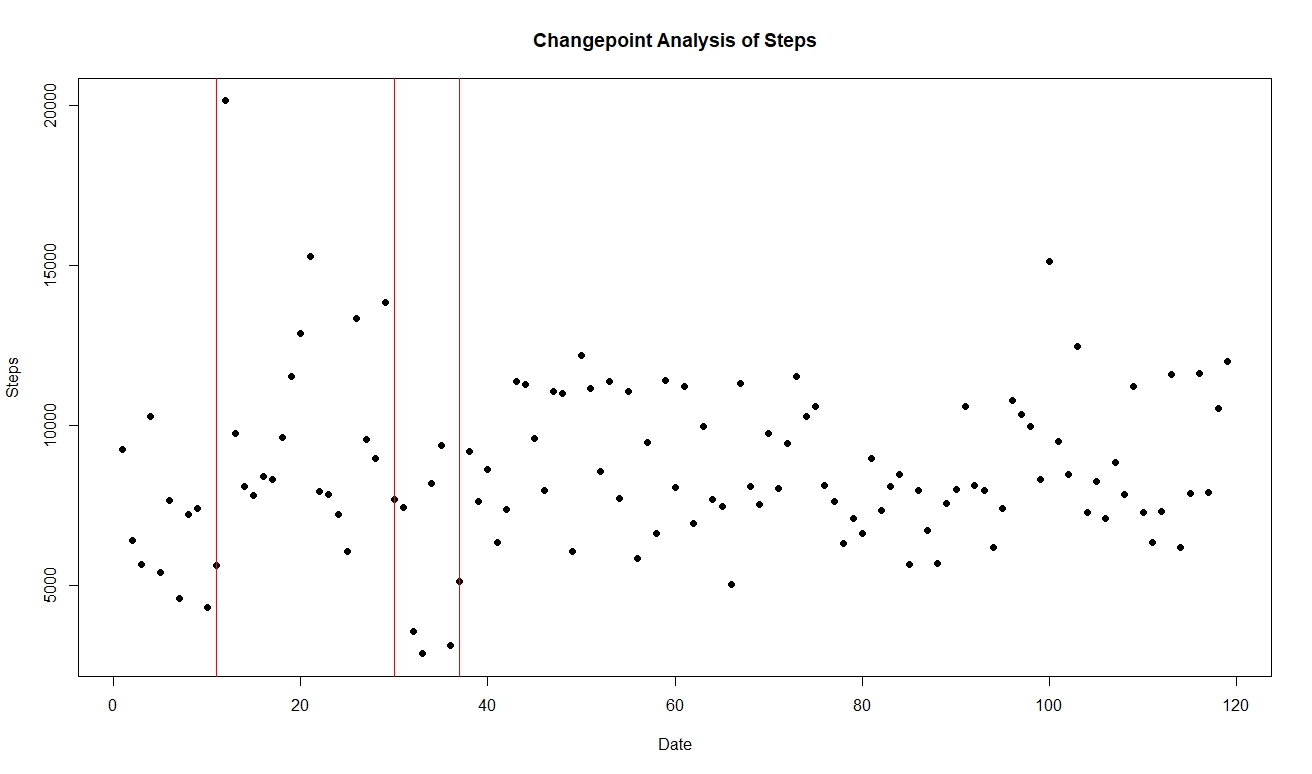
Using cpt.np, changepoints detected at 8/8/18, 8/27/18, and 9/3/18
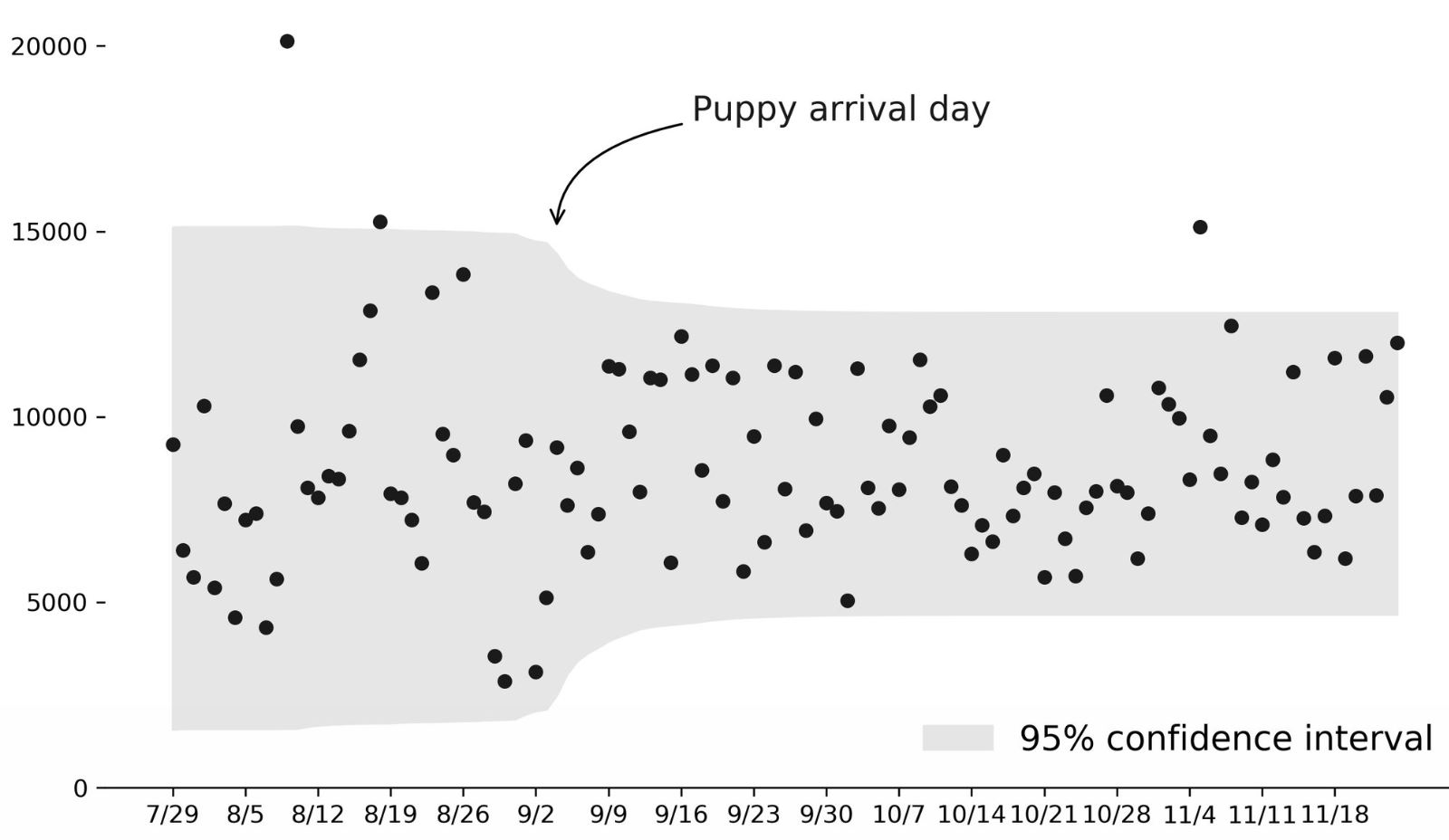
Here is Ash's steps count data with his analysis
Summary
These results are all fairly consistent with identifying the change point around 9/1/2018, with the exception of cpt.mean which in this case is strongly influenced by the outlier around 8/9/18. Is that a good or bad thing? It depends. For example, you could have a manufacturing process where you'd want to be informed right away if there is a process change. On the other hand, intuitively I feel that one outlier shouldn't be able dictate an entire analysis (unless you want it to). For these reasons, I recommend cpt.meanvar or especially cpt.np as being more reliable on the frequentist side. For the Bayesian side, I'd like to see how sensitive the analysis is to using different priors and hyperparameters.
I believe changepoint analysis is a (yet another) great example of the importance and success of hypothesis testing, something which is currently en vogue to critique. Killick and Eckley write
"The detection of a single changepoint can be posed as a hypothesis test. The null hypothesis, H0, corresponds to no changepoint (m = 0) and the alternative hypothesis, H1, is a single changepoint (m = 1)"
Thanks for reading.
Please anonymously VOTE on the content you have just read:
Like:Dislike: