AURA
4/15/05
- INTRODUCTION
By examining data we can attach tangible quantities to the "intangible qualities" related to readers and readings and get some understanding about these, and other, questions. A necessary first step to approaching more difficult questions is to focus on the simpler ones. There is not much or any actual cumulative data on these subjects.
Up to date, there have been numerous analyses of transcripts, but many of these are of little use for some of the following reasons
- readings are from a non-live setting so editing cannot be ruled out
- the existence and/or content of the readings is non-verifiable
- reader is self-proclaimed
- reading analysis has no connection to other analyses
- no standardized transcript and reading identifiers
- the analysis is a non-numerical comparison, or
- the analysis is too complex numerically, creating a large burden for each reading analysis
- the analyses are presented in a biased/hostile manner and/or environment
- the only intended focus is on mediums
This informal article introduces AURA, the Archive of MediUm and Cold Reader DAta. AURA is an Excel file that is a repository of various data of professional mediums and cold readers from their live readings, which will be used to calculate descriptive statistics for the data collected. It is more importantly a request, by example, for an ongoing, structured method to record data relating to professional readers from verifiable live readings.
Errors are bound to creep in when doing tedious work, and they certainly exist here. My goal is to not make them, but when I do, find and correct them. People are welcome to submit their suggestions and calculations, and they will be reviewed, and changes will be made if needed. Also, if you've found some transcripts that meet the quality criteria (live reading, professional reader, verifiable source), please let me know.
Terminology
- Caller: person getting the reading, over the phone (including internet)
- Cold reader: a person claiming to be able to simulate what the medium does, but solely by using the techniques (cold, warm, and hot reading) of mentalism (a branch of magic), and makes a large portion of their living from this
- Data: information represented by number or character, to be used in this analysis to compute descriptive statistics to draw conclusions about a sample
- Medium: a person claiming to be able to receive information from the deceased, or spirits, or other realms/dimensions, and who makes a large portion of their living from this
- Reader: a neutral term for a medium or a cold reader
- Reading: a single live encounter between a reader and a sitter, attempting to talk or actually talking about the deceased, which is broadcasted as it is happening, or with a small delay, rather than from a recording. It must be possible for anyone to obtain the transcript and audio/video recording of the reading for closer inspection if needed
- Sitter: person getting the reading, in person
- Transcript: readings recorded in writing
What is being studied?
The unit of analysis is a reading, denoted by R. A transcript, denoted by T, is a collection of text from the readings of readers and sitters. A transcript contains at least one reading. A generic transcript looks like
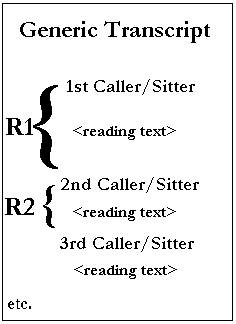
and each transcript will be edited to show the reading numbers. For example, transcript 10, or T10, contains reading 100, or R100, and will have "R100" in the left-hand margin at the start of the reading in the transcript. To refer to this reading, instead of saying "The reading on Larry King Live from September 6, 2002 with John Edward where he talks about a young male, death from an impact, a D connection..." and etc., simply refer to T10R100.
The structure of AURA
The AURA file has reading numbers as rows, and the variables being kept track of for each reading as columns.

Variable descriptions
- Update: number of the update
- Notes for Update: items that were updated for that update
- Update Date: date of the update
- TranscriptID: unique number assigned to identify a transcript
- Source: verifiable source where the transcript was obtained
- ReadingID: unique number assigned to identify a reading
- ReadingDate: date the reading took place
- ReaderType: "C" for cold reader, "M" for medium
- ReaderName: name of reader
- ReaderGender: gender of reader
- SitterLocation: geographical location of sitter
- SitterPersonWhoPassed: person(s) who sitter says has passed, usually person(s) they would like to contact
- PersonReaderSays: deceased person(s) who reader talks about directly or refers to
- ReaderPersonBeforeSitterPerson: 1 if the reader made a statement about the specific deceased person(s) before the sitter mentioned the person(s), 0 otherwise
- SitterCause: cause(s) of death that the sitter says
- ReaderCause: cause(s) of death that the reader directly says or refers to
- ReaderCauseBeforeSitterCause: 1 if the reader made a statement about the specific cause(s) of death before the sitter mentioned the cause(s), 0 otherwise
- LettersReaderSays: letters the reader says
- NamesReaderSays: names reader says
- DoYouUnderstand: number of times reader says "Do you understand?" type of questions
- RememberThis: number of times reader says "Remember this." type of statements
- QuestionsAskedToSitter: number of times reader asks questions
- SitterGender: gender of the sitter
- allletters: a master list of all letters said by all readers
- allnames: a master list of all names said by all readers
- statename: column of the names of the states in the United States
- state: Federal Information Processing Standard (FIPS) code for each state
- sitterlocationfrequency: number of sitters from that state
- AURA FILE AND TRANSCRIPTS
(this webpage houses the official copy of AURA)
| T1.txt (R1-R5) | T2.txt (R6-R27) | T3.txt (R28-R48) | T4.txt (R49-R50) | T5.txt (R51-R55) | |
| T6.txt (R56-R60) | T7.txt (R61-R71) | T8.txt (R72-R79) | T9.txt (R80-R92) | T10.txt (R93-R104) | T11.txt (R105-R121) |
| T12.txt (R122-R139) | T13.txt (R140-R160) | T14.txt (R161-R180) | T15.txt (R181-R197) | T16.txt (R198-R221) | T17.txt (R222-R241) |
| T18.txt (R242-R257) | T19.txt (R258) | T20.txt (R259-R273) |
T21 coming soon
|
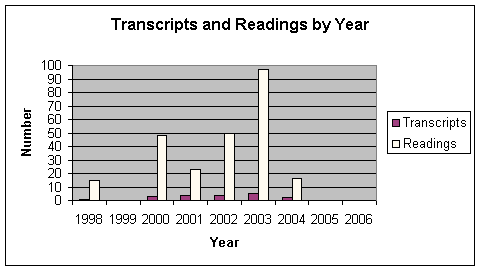
- NUMBER OF TRANSCRIPTS AND READINGS BY YEAR
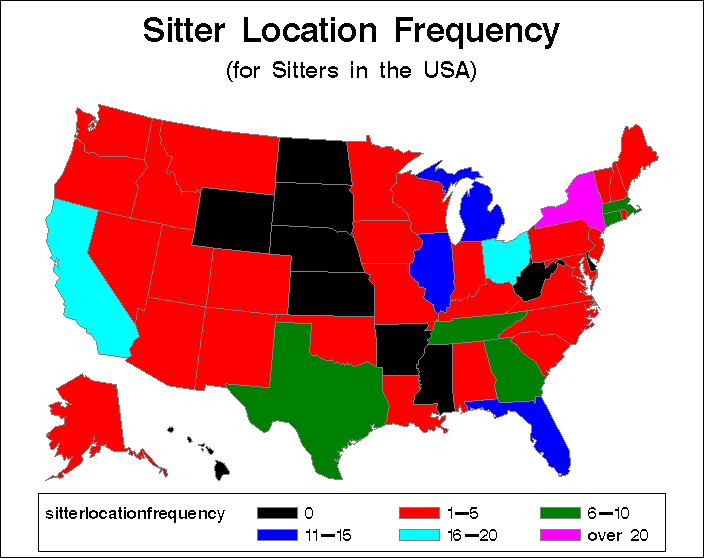
- MAP OF SITTER LOCATION FREQUENCY (USA sitters)
- READER AND SITTER GENDER PERCENTAGES
Reader
Male: 40%
Female: 60%
Sitter
Male: 5.49%
Female: 53.48%
Unknown: 40.66%
- PERCENTAGE OF TYPE OF READER
Cold reader: 0%
Medium: 100%
- PERCENTAGE OF READINGS BY READER
Char Margolis: 8.79%
James Van Praagh: 20.15%
John Edward: 27.84%
Rosemary Altea: 9.89%
Sylvia Browne: 33.33%
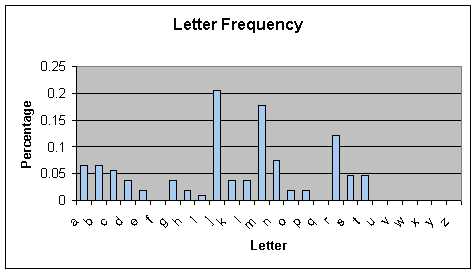
- FREQUENCY OF SINGLE LETTER SAID BY READERS
- LIST OF FREQUENTLY OCCURRING FIRST NAMES FROM THE 1990 CENSUS
(source)
1. James, Mary
2. John, Patricia
3. Robert, Linda
4. Michael, Barbara
5. William, Elizabeth
6. David, Jennifer
7. Richard, Maria
8. Charles, Susan
9. Joseph, Margaret
10. Thomas, Dorothy
- NAMES SAID BY READERS (AND FREQUENCY)
Aaron Abbey Abigail Alan Angela Ann(3) Anna(3) Annie Anthony Antonette
Barbara Beth Betty Bill(3) Billy Bobby Boston Brooklyn Bud Buddy Burgess
Carol Catherine Cathy Charles(2) Chris Chrissy Cinnamon Cook Cooke
Dale Dan(2) Danny Dave David(2) Diane Donna(2)
Ed(2) Eddie Edgar Edward Eleanor Eleanore Elizabeth(2) Ellen(4) Emily
Gerald
Harold Harry Helen(4)
Jack James(2) Jamie Jane(3) Janet(2) Janette Janey Janice Jeannie(2) Jenny Jerry Jim(3) Jimmy(4) Joan(2) Joanne(2) Jody Joe(6) Joey(2) John(7) Joseph(3) Josephine Josie Joyce Judy June
Karen Katherine Kathleen Kristen
Laura(2) Lewis Liz Lori Lorraine Louis
Maddy Malcolm Margaret(6) Margie(2) Mariam Marie Mary(8) Maureen(4) Max Melissa Michael(2) Mike Mikey Mildred Millie Myrtle
Nat Nate Nathaniel New York
Obo
Paul(3) Pauley Pepper Peter Phil Phillys
Rich(2) Richard Richie Rickie Rita Robbie Robert(4) Roberta Ronald(2) Ronnie Ronny Rose Ruth(2)
Salty Sam Sarah Saul Sharon(2) Sherie(2)
Taylor Thomas(2) Tim Tyler
Ubi
William
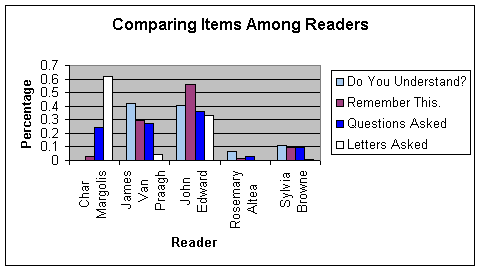
- PERCENTAGE OF 'DO YOU UNDERSTAND?' TYPE OF QUESTIONS, 'REMEMBER THIS.' TYPE OF
STATEMENTS, TOTAL QUESTIONS ASKED, AND LETTERS SAID FOR READERS COMPARED WITH EACH OTHER
- PERSON AND CAUSE MATCHES
The term "match" in these instances is more descriptive than the term "hit", which is commonly used in the skeptical literature.
I reason there are only 4 types of matches:
- Type 1: the percent that the person/cause the sitter talks about matches the person/cause the reader talks about
- Type 2: Type 1, but the reader made a statement about the specific person/cause before the sitter said the person/cause
- Type 3: Type 2, but with the statement by the sitter being verified as a fact. These are beyond the scope of this study
- Type 4: Type 3, but in an experimental setting (blinding, randomization, etc.). These are beyond the scope of this study.
As the Type increases, the measure of a match gets less naive.
The percentages are for the readers as a whole.
Deceased person match percentages
Type 1 match: 61.17%
Type 2 match: .37%
Cause of death match percentages
Type 1 match: 11.36%
Type 2 match: 1.1%
THANK YOU ! :-)
I'd like to thank the following people for their support: Clancie from the JREF message board.
Please anonymously VOTE on the content you have just read:
Like:Dislike: