Stuttering Frequentists
1/10/19
Over at Bayesian Spectacles, they recently posted The Story of a Lost Researcher Trying to Learn About Disruptive Behaviors During the Full Moon.
In it, they write that there are 4 types of people that don't use Bayesian methods:
- Those that are resistant: This group of researchers is the most difficult to address. They know exactly what the Bayesian approach is and how it works. But for whatever reason they stay resistant and prefer the common, frequentist approach.
- Those that are oblivious: There are those, unfortunately, that have never heard of the Bayesian approach. How is this possible? This group most likely consists of on the one hand inactive researchers and on the other students that are still solely taught the frequentist approach.
- Those that are lazy: Even though it has been their New-Year's Resolution for the last five years, these researchers haven't managed to learn more about the Bayesian approach and how to implement it. Consequently, they are not sufficiently confident to adopt the Bayesian framework.
- Those that are lost: Last of all, this group has heard of the Bayesian approach, is aware of its benefits, and knows the mathematical background. These researchers would like to apply the Bayesian approach but do not know what statistical software to use. In the end they resort to using the common frequentist analysis, saving them hours of programming.
It may not occur to Bayesian (rose colored?) Spectacles that a subset of 1. could in fact just be people that understand Bayesian methods well, have used them, and came to the conclusion that Bayesian methods:
- have problems with subjectivity, brittle priors, Bayes factors, and Drake-equation-ness
- may not deliver enough bang for the buck
- may not address probability, but only "uncertainty", "belief", or "chance"
- also suffer from questionable research practices
- pale in comparison to successes from frequentist work in experimental design, quality control, and survey sampling
To drive their points home, they present an advertisement for their software JASP using an absurd scenario: a statistician who is totally confused by a frequentist approach but totally nails the Bayesian approach. Well, put aside the fact that the general public doesn't understand how to solve a quadratic equation, let alone understand p-value logic, are we then supposed to believe the same people do understand the intricacies of priors and MCMC calculations in a Bayesian approach?
Here are a few of the graphics they used:
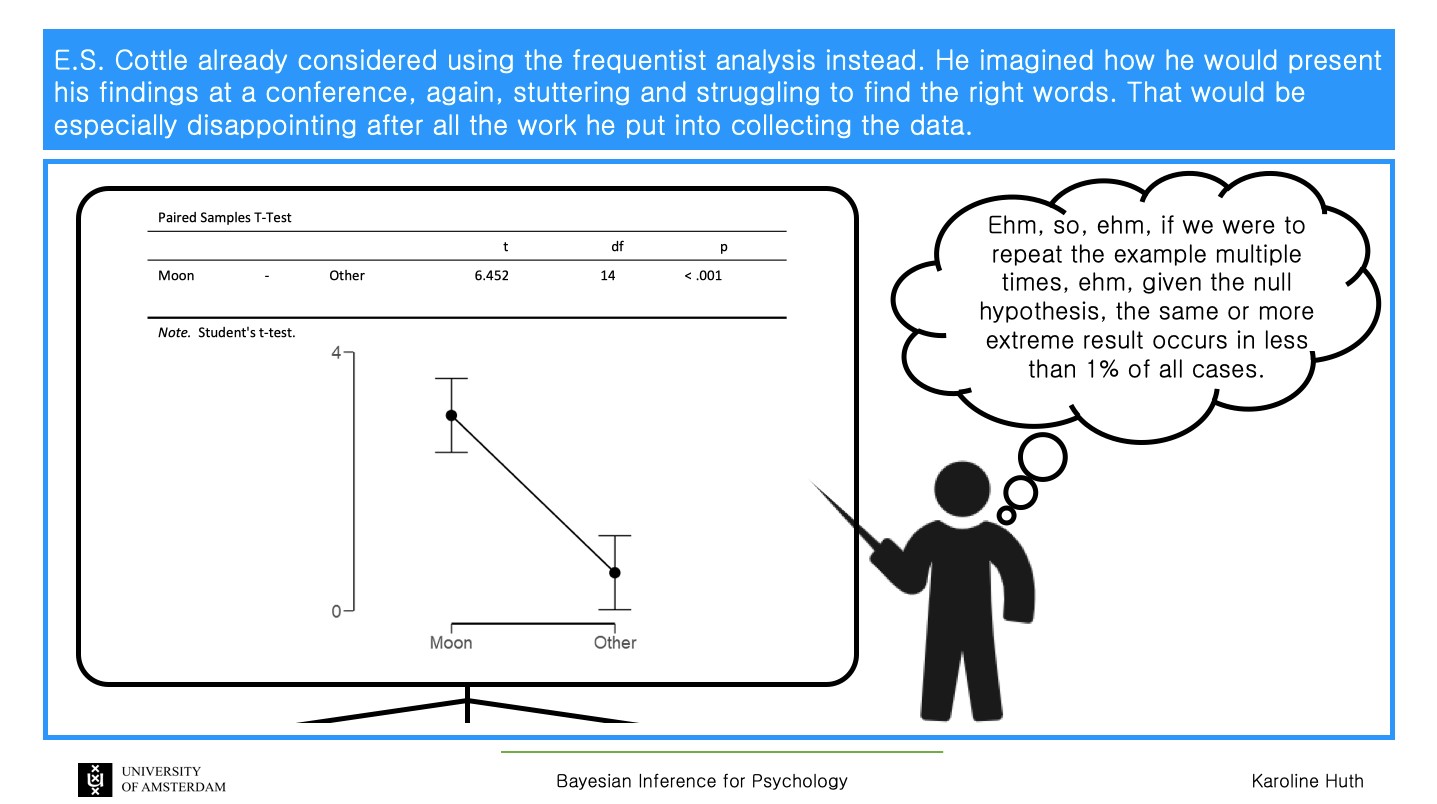
Of course, it is advantageous to Bayesian Spectacles to try and equate "frequentism" with "p-values" or "NHST" (ie. null hypothesis significance testing), since some people misunderstand p-values and testing, however frequentism is much more than just those topics. Misunderstandings are, of course, no reason to throw out the baby with the bath water. In any case, a p-value is just a distance our test statistic, based on our data, is away from our assumed model. The logic of modus tollens says P->Q, and if we observe not Q, therefore we conclude not P. Note that P is the null hypothesis H0, and Q is what we'd expect the test statistic T to be under H0. A concrete example is, we agree on assuming a fair coin model. We therefore expect about 50 heads if we flip a coin 100 times. However, we observe 96 heads (96 put on a p-value scale would be an extremely small p-value). Therefore, we conclude the fair coin model is not good. Ideally, of course, we would want to perform our experiment more than one time. Fisher stated that
...we may say that a phenomenon is experimentally demonstrable when we know how to conduct an experiment which will rarely fail to give us a statistically significant result.
This type of logic is valid and essential for falsification and good science.
They also do not present any explicit confidence interval here. That's too bad, since the frequentist confidence interval gives a nod to objectivity and replication. Using JASP, we get a 95% confidence interval of [1.624, 3.241] using a Student t-test, and [1.575, 3.320] using the nonparametric Wilcoxon signed-rank test.
They seem to dislike the idea of hypothetical repetitions (ie. counterfactual argumentation) with frequentism, but have no problem using all values of a prior/posterior that has a continuous distribution or the thousands of realizations from a MCMC with Bayesian methods, or hypothetically repeatedly playing darts with the Bayes factor pizza charts, all of which are using hypotheticals they didn't actually observe. Others pretend that Bayesian updating, that is using posteriort from the current experiment as the priort+1 in the next experiment, is actually done in practice, when it is only hypothetical.
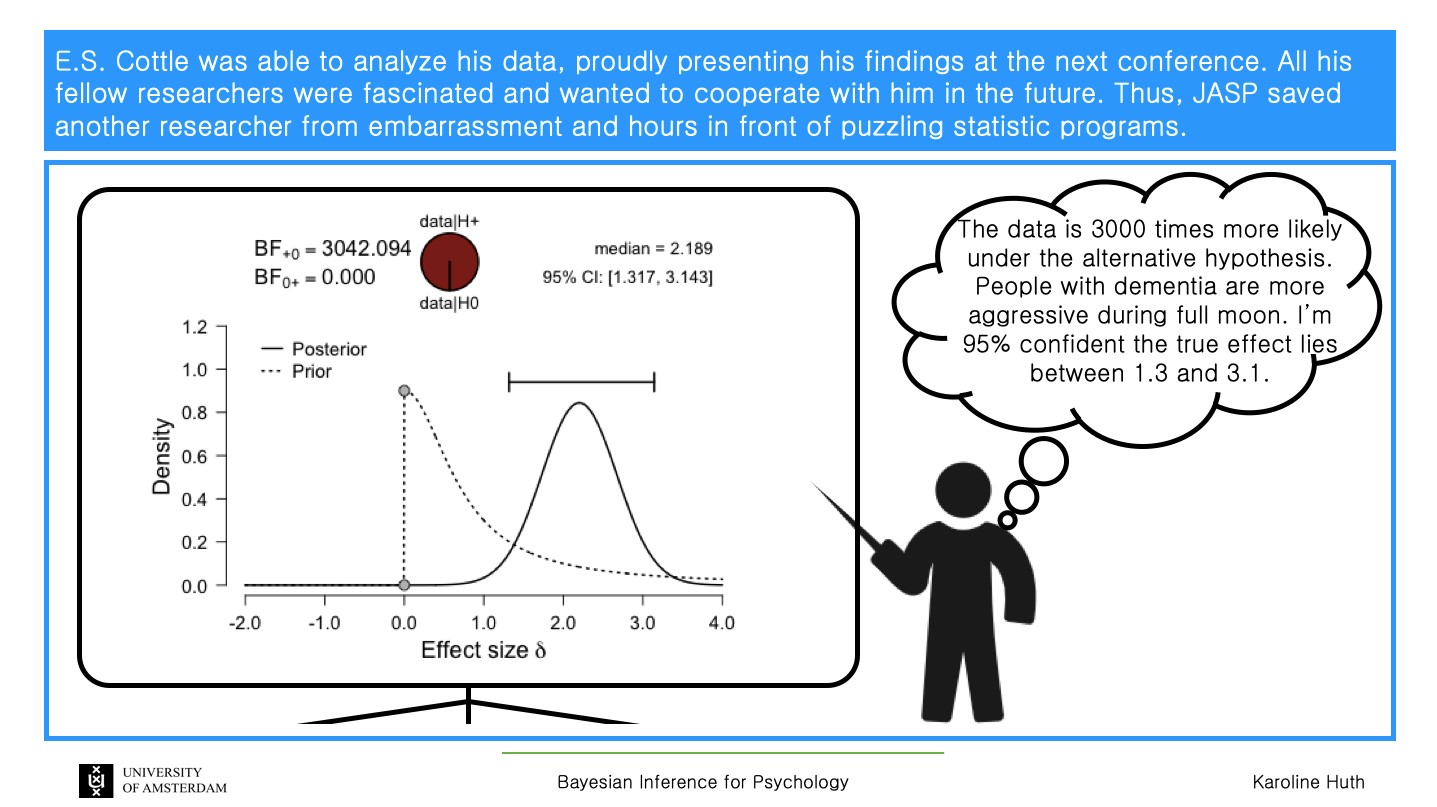
In the Bayesian example, I believe they use a default Cauchy prior with a certain scale parameter (1/2.5 ~ .707). They do not discuss how they came up with their prior (is it from actual experiments, for example), nor present how the analysis would change if they were to have used different priors (ie. no sensitivity analysis was done) and different hidden MCMC settings. If you change these you can get similar, slightly different, or very different Bayes factors and intervals, and perhaps conclusions.
The frequentist graphic, besides being insulting to those that have speech impediments, is insulting to those of us that do know how to interpret frequentist statistics and understand the flaws that can be present in Bayesian approaches. The frequentist approach is fatally flawed only in JASP's strawman presentation / sales pitch.
Thanks for reading.
Please anonymously VOTE on the content you have just read:
Like:Dislike: