A Demonstration of Correlation Fixation
12/22/10
The basic idea of correlation is ancient, but the modern measure of it was developed by Karl Pearson in 1895 based on work by Francis Galton in 1885. The Pearson correlation coefficient is one of the most widely used, and useful, statistics. Unfortunately, it is also one of the most widely misused statistics...but that isn't Karl's or Francis's fault. This article demonstrates a misuse of correlation that I've witnessed, and discusses alternatives.
Your supervisor has given you an assignment to determine if missing SALES can be imputed using PAYROLL. You reason that if there is large correlation between SALES and PAYROLL the answer is "Yes".
The sample correlation between two variables X and Y is calculated as
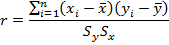
where 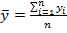 and
and 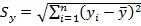 .
.
You proceed to calculate a correlation coefficient, and get r = .816. That is large you reason, and you report to your supervisor that SALES and PAYROLL are correlated, and then proceed to carry out imputation. You may have made at least two mistakes!
Mistake # 1: Not making a graph
Anscombe (1973) provided a classic example of four datasets with equal correlation coefficients (.816), but with completely different graphs.
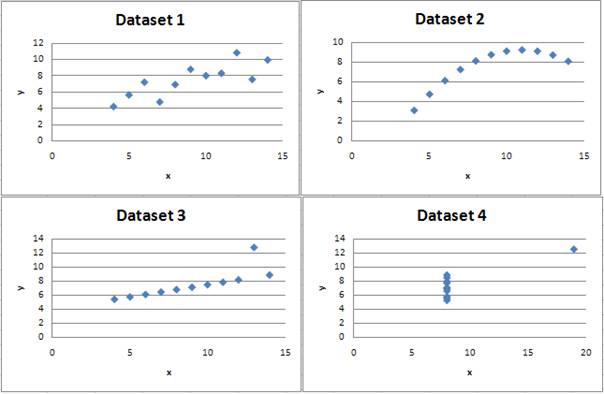
Datasets 1 and 3 are the only datasets for which the correlation coefficient would be a sensible measure. Dataset 2 isn't even linear, and Dataset 4 has one obvious outlier. It is probably a good idea to also consider transformations of the data too, because we often deal with skewness in economic data.
Mistake # 2: Not taking survey weights into account
If we're working on a survey, we need to consider the impact of survey weights in everything we do. There happens to be a weighted version of the correlation coefficient, which is
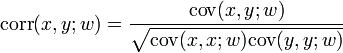
where
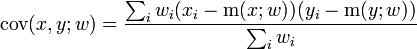
and
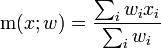
A generalization of this mistake is "Are you calculating the right measure"? There are nonparametric measures of correlation or association you can calculate which may be more appropriate, such as Spearman's rank correlation and Kendall's tau. Also, if you are looking to replace X with Y, say replace missing SALES with non-missing ADMINSALES, then you probably don't want a measure of correlation, but a measure of agreement, something like a concordance correlation coefficient (see Lin, 1989).
The main takeaway from this discussion is to not use a technique just because it is the only one you know or because it is the only one your software gives you - that can be a recipe for making incorrect decisions. Before doing any formal statistical test always consider "low tech" approaches like making graphs and looking at summary statistics. Consult your local library or for statistics books that may answer your questions. Bounce ideas off your peers who may have more expertise with theoretical and applied statistics. Others may have encountered a similar situation in prior work.
Please anonymously VOTE on the content you have just read:
Like:Dislike: